버퍼 vs 슬라이딩 윈도우:
앞서 다뤘던 슬라이딩 윈도우는 TCP에서 데이터 흐름을 제어하는 매커니즘인데, 송신자가 한번에 전송할 수 있는 데이터의 양을 제한하고, 수신자가 수신할 수 있는 데이터의 양을 제어함. 송신 윈도우 & 수신 윈도우의 두 개 윈도우로 구성됨.
버퍼는 라우터, 스위치, 컴퓨터 등의 네트워크 장치에서 임시로 데이터를 저장하는 메모리 공간. 곧 다룰 라우터 버퍼는, 라우터에 붙어서, 데이터 패킷을 일시저장하고, 전송 지연을 관리하는 버퍼임.
Congestion 혼잡이란, 여러 소스가 동시에 너무 많은 데이터를 네트워크게 빠르게 전송할 때 발생.
예를 들면 아래와 같은 시나리오들을 포함한다.
* 시나리오 1: 2 송신, 2 수신, 무한 버퍼 라우터, 재전송 없음

위에서 보이듯, 무한 버퍼이기 때문에 패킷 손실은 없지만, 최악의 경우 끝도 없이 딜레이가 걸릴 수 있음...
그냥 잠깐 '버퍼가 커지는 거' 라고 생각하면 문제 없어보이지만, 문제는 버퍼가 커지는 것 그 자체가 네트워크의 성능을 저하시킨다는 것. 버퍼가 커지고, 진행시켜야 하는 버퍼의 양은 많아지는데 네트워크는 오히려 성능이 저하되어 진행속도는 느려지고, 종국적으로 거의 진행이 불가능한 시점까지 가는 것이다.
* 시나리오 2: 하나의 라우터, 유한 버퍼

유한 버퍼이기 때문에 가득 찼을 때 새로이 송신된 데이터 패킷들은 버려짐. 이를 인지한 송신자들은 패킷을 다시 보내고, 이 과정에서 지속적인 패킷 손실이 생기고, 불필요한 추가 혼잡을 야기함.
=>
* 유한 버퍼: 버퍼가 차도 패킷은 전송되기 때문에 이미 가득 찬 버퍼에 당도하는 버퍼는 유실될 수 있음. 그렇기에 재전송 시스템이 있는 것. 고로 유한 버퍼 + 재전송은 세트로 간다. 재전송이라는 행위가 그 자체로 패킷의 양을 증가시키고 혼잡을 야기한다.
재전송은 2가지 방식이 있는데,
첫번째는 타임아웃. 수신을 한 것에 대해서 수신기가 ACK를 보내는 방식인데, 설정한 시간 내에 송신기에 ACK가 돌아오지 않는다면 재전송하는 방식.
두번째는 중복 ACK. 수신을 하지 못한 것에 대해서 수신기가 ACK를 보내는데, 해당 ACK를 여러 번 (보통 3회) 수신기가 받으면 송신기가 재전송하는 방식.
알아둘 것이, 중복 ACK는 어쨌든 해당 패킷에 문제가 있을지언정 송수신 연락망에는 문제가 없다는 의미인데 (수신자로부터 송신자로 ACK가 오므로), 타임아웃의 경우 ACK가 아예 안 오는 것을 의미하므로 연락망 자체의 중대한 문제일 수 있음.
* 무한 버퍼: 패킷 손실될 일은 없지만, 송신이 수신보다 빠를 경우 버퍼의 크기가 크게 증가함. 버퍼가 커지는 것은 네트워크 성능 저하를 불러오고, 진행이 아예 안 되는 상태까지 악화될 수 있음.
이렇게 재전송이 연속되면 Congestion Collapse를 불러오고, 이는 효율을 급감시켜 말그대로 붕괴로 이어짐.

TCP 혼잡 제어 - TCP Congestion Control
그래서 UDP와는 다르게, TCP(Transmission Control Protocol)는 여러가지 혼잡 제어 매커니즘을 사용함. 송신자가 네트워크의 혼잡 상태를 추정(실시간 대역폭 추정)하고, 이에 따라 데이터 전송 속도를 조절하여 네트워크 성능을 최적화하고 혼잡을 방지함. 참고로, 이 '대역폭'이라는 건 정해진 값이 아니라, 지속적으로 바뀌기 때문에 계속해서 측정해나가면서 업데이트할 수 밖에 없다.

기본적으로 혼잡 창 - Congestion Window, cwnd - 을 활용함. 혼잡 창은, 송신자가 네트워크 혼잡을 고려하여 전송할 수 있는 데이터의 양을 결정함. 송신자가 데이터를 전송할 때, 송신자는 cwnd와 수신 창(rwnd) 중 작은 값을 선택하여 데이터를 전송함.
혼잡 제어는 두 가지 주요 단계로 나눌 수 있음 - 1 느린 시작 과 2 혼잡 회피. 근데 솔직히 이런 용어가 쓸데없이 더 헷갈리게 만드는 것 같다. 저 둘의 차이는 그냥, cwnd 크기를 얼마만큼씩 늘리냐 밖에 없다. 2배씩 늘리면 느린 시작, 1씩 늘리면 혼잡 회피. 그러니까 둘을 구별하지 말고 그냥 혼잡 제어를 통째로 이해하자.
혼잡 제어 과정
1) 1 MSS의 cwnd 크기로 시작, 즉 패킷 하나 전송하고 ACK를 돌려받음을 확인함 - 1개는 감당가능하다는 뜻.
2) 2, 4, 8, ... 이렇게 지수적으로 cwnd 크기를 늘려가며 ACK를 돌려받음을 계속 확인, 이걸 cwnd가 ssthresh에 도달할 때까지 반복함 (참고로 ssthresh의 초기값은 대역폭의 추정치로 가정한다고 한다. 이 ssthresh는 실제 대역폭보다 클 수도, 작을 수도 있음, 크면 이후의 "2. 혼잡 회피" 처럼 행동함. 이해 안될 듯. 그냥 읽도록.)
------ssthresh에 도달하면 a.k.a. 혼잡 회피 (Additive Increase, Multiplicative Decrease (AIME))의 시작------
3) ssthresh에 도달했는데도 ACK가 잘 돌아오면, 대역폭보다 ssthresh가 작다는 뜻이므로, 계속 cwnd 크기를 높여 나간다. 그러나, 이제 대역폭에 가까워졌다는 것을 인지했기 때문에 cwnd를 2배씩 늘리는 대신 1씩 증가시킨다.
4) 증가시키다가,
- 중복 ACK가 발생하면, 덜 심각한 네트워크 혼잡이므로, 빠른 재전송 + cwnd/2 + 혼잡회피 유지(3)으로 돌아감)하고,
- 타임아웃이 발생하면, 심각한 네트워크 혼잡으로 추정되므로, cwnd==1 + 느린시작으로 전환(1)로 돌아감)함.
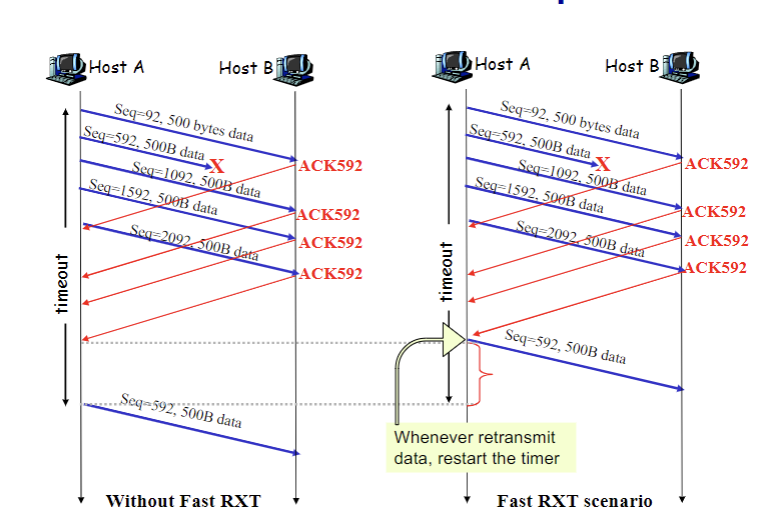
* 두 경우 모두 ssthresh는 절반으로 나눈다.
'CS 전공수업 > 컴퓨터 네트워크' 카테고리의 다른 글
| [네트워크] QUIC 프로토콜 (1) | 2024.06.04 |
|---|---|
| [네트워크] 네트워크 보안 (0) | 2024.06.04 |
| [네트워크] ARQ: Stop-and-wait, Go-back-N, Selective repeat (0) | 2024.05.06 |
| [네트워크] 전송계층 - TCP와 UDP, 그리고 (De-)Multiplexing (1) | 2024.05.06 |
| [네트워크] 응용계층 - HTTP & DNS, google.com을 치면 일어나는 일 (0) | 2024.05.05 |



