GROUP BY는 기본적으로, 데이터 그룹화 및 집계 작업의 핵심 기능임. 데이터를 특정 컬럼 값에 따라 그룹으로 묶고, 각 그룹에 대해 집계 함수를 적용할 때 사용됨.
예를 들어, employees 라는 테이블이 있고, employee_id, department_id, job_id, salary가 있을 때,
특정 부서의 특정 직위가 받는 평균 연봉이 얼마인지 확인하려면 어떻게 해야하나?
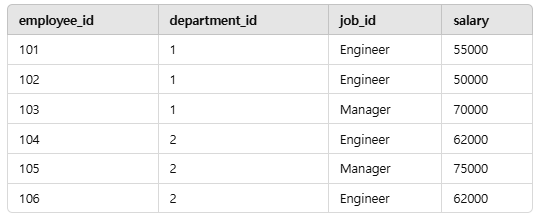
group by를 써서 딕셔너리로 치면 "key"가 되는 튜플을 만들어주면 됨.
SELECT department_id, job_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id, job_id;
그럼 결과적으로
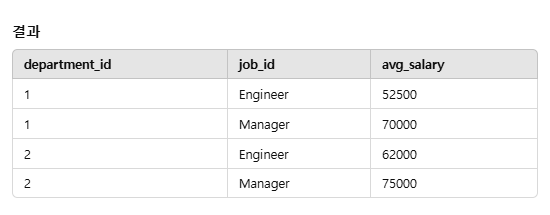
이렇게 dep_id와 job_id를 묶어서 하나의 key로 만든, 새로운 차트가 등장한다.
=> 그러니까 핵심은, group by를 쓰게 되면 새로운 key가 생긴다는 것과, 보통은 그 key를 기준으로 새로운 row들이 생기면 그걸 AGGREGATE FUNCTION을 활용해서 변형시켜준다는 것.
* GROUP BY에 해당하는 COLUMN의 경우, SELECT에서 꼭 언급을 해줘야 하며, 반대로 GROUP BY에 없는 것을 SELECT에서 집계함수를 쓰지 않고 쓸 수는 없다. 즉, 무조건 GROUP BY에 있거나, 집계함수의 대상이 되는 두개의 케이스 중 하나만 SELECT에 쓸 수 있다.
또한, 함께 자주 활용되는 CASE 함수의 경우,
단순 case의 경우 - 특정 컬럼의 값에 따라 조건을 비교하고 값을 반환한다

검색 case의 경우 - 특정 컬럼이 아닌 condition에 다 집어넣음.

자동차 대여 기록에서 대여중/ 대여 가능 여부 구분하기
진짜 생각할 거리를 많이 던져 준 좋은 문제다.
1 각각의 차가 여러번 등장한다.
그래서 distinct를 쓰든, group by를 쓰든 해서 중복되는 엘리먼트들을 쳐내줘야 하는데,
distinct의 경우 select에 해당하는 모든 아이들을 포함해야 하므로 이 문제를 푸는 데에 적절하지 않다.
그래서 group by로 묶어줬다.
2 대여중 혹은 대여 가능: 만약 값이 between 이면 넣고, 아니면 마는 방식인데, between 이라는 함수 활용.
3 그리고 '대여중'인 '대여 가능' 이거 두개를 선택해야 하는데, 각각의 car_id에 해당하는 수많은 내역 중에 지금 저 날짜에 대여중이라면 대여중, 아니면 가능을 넣어주는 거다. 즉, 대여중이 하나라도 있으면 대여중을, 대여 가능 밖에 없으면 대여 가능을 넣어줘야 한다. 그걸 구현하는 방법으로 CTE를 써서 대여 중이 한번이라도 있으면 car_id를 포함하는 테이블을 만듦으로써 이를 활용하는 식으로 진행했다.
4 저렇게 테이블을 만들고 나면, 이걸 활용할 때 어쩔 수 없이 또 (select 어쩌고)를 쓰는 방식의 서브쿼리를 써야 하는데, 그게 싫으면 with의 테이블 안에 값을 넣어줘도 될 것 같다. 그치만 이후에 join을 배우면 좀 더 쉽게 풀 수 있지 않을까 싶다.
결과적으로 내 코드는
with availability_table as (select car_id from car_rental_company_rental_history where '2022-10-16' between start_date and end_date)
select car_id, case when car_id in (select car_id from availability_table) then '대여중' else '대여 가능' end availability
from car_rental_company_rental_history
group by car_id
order by car_id desc
대여 횟수가 많은 자동차들의 월별 대여 횟수 구하기
이 문제는 참 골치 아픈 문제였다.
8월부터 10월까지의 대여횟수가 5회 이상인 차들의 id를 확보해야 했고, 해당 차들의 레코드들을 월별로 나눠줘야 했다. 그래서 두 개의 테이블을 생성해서 이 둘을 활용했다.
with로 두 개 이상의 테이블을 만들 때는 ,로 구분해주고, with는 한번만 써주고.
또 month() 형태는 ansi에 위배되므로 extract(month from)의 형태로 바꿔줘야 한다.
그리고 where는 테이블 형성 과정에서 영향을 미치기 때문에, 이미 만들어진 테이블에 대해서 활용할 수 있는 aggregate function을 사용할 수 없다. 그래서 group by의 having 절 안에서 이를 활용해주면 그만이다.
내 코드는
with targets as (select car_id, count(*) count from car_rental_company_rental_history where start_date between '2022-08-01' and '2022-10-31' group by car_id having count(*)),
monthly_count as (select car_id, extract(month from start_date) month from car_rental_company_rental_history where start_date between '2022-08-01'and '2022-10-31')
select mc.month, mc.car_id, count(*) records
from monthly_count mc join targets as t1 on mc.car_id = t1.car_id where t1.count >= 5
group by mc.car_id, mc.month order by mc.month, mc.car_id desc
저자 별 카테고리 별 매출액 집계하기
여러모로 골치 아프지만, 잘 묶어서 생각하다보면 잘 풀 수 있다.
with jan_sales as (select book_id, sum(sales) total_sales from book_sales where sales_date between '2022-01-01' and '2022-01-31' group by book_id),
book_w_author_name as (select b.book_id, b.category, b.author_id, b.price, b.published_date, a.author_name from book b join author a on b.author_id = a.author_id)
select b.author_id, b.author_name, b.category, sum(j.total_sales*b.price) total_sales from jan_sales j join book_w_author_name b on j.book_id = b.book_id
group by b.author_id, b.category
order by b.author_id, b.category desc
식품분류별 가장 비싼 식품의 정보 조회하기
with max_table as (select category, max(price) max_price from food_product group by category having category in ('과자', '국', '김치', '식용유'))
select f.category, m.max_price, f.product_name from food_product f join max_table m on f.category = m.category where m.max_price = f.price order by m.max_price desc
자동차 종류 별 특정 옵션이 포함된 자동차 수 구하기
varchar의 일부도 속했는지 여부를 확인하는 방법은, <해당 varchar> like "%시트%" 이렇게 표현해주면 됨.
with yes_options as (select * from car_rental_company_car where options like '%시트%')
select car_type, count(*) cars from yes_options group by car_type order by car_type
성분으로 구분한 아이스크림 총 주문량
select ingredient_type, sum(total_order) total_order from icecream_info i join first_half f on f.flavor = i.flavor group by ingredient_type order by total_order
진료과별 총 예약 횟수 출력하기
별칭으로 사용하기 위해서는 작은 따옴표는 안되고, 큰 따옴표 혹은 백틱을 활용해야 한다고 함.
작은 따옴표는 string 취급 받는다고 함.
select mcdp_cd as '진료과 코드', count(*) as '5월예약건수' from appointment where apnt_ymd between '2022-05-01' and '2022-05-31' group by mcdp_cd order by count(*), mcdp_cd
카테고리 별 도서 판매량 집계하기
select b.category, sum(s.sales) total_sales from book b join book_sales s on b.book_id = s.book_id where s.sales_date between '2022-01-01' and '2022-01-31' group by category order by category
즐겨찾기가 가장 많은 식당 정보 출력하기
with favorite_foods as (select food_type, max(favorites) favorites from rest_info group by food_type)
select r.food_type, r.rest_id, r.rest_name, r.favorites from rest_info r
join favorite_foods f on r.food_type = f.food_type where r.favorites = f.favorites order by food_type desc
조건에 맞는 사용자와 총 거래금액 조회하기
select u.user_id user_id, u.nickname nickname, sum(b.price) total_sales
from used_goods_user u join used_goods_board b on b.writer_id = u.user_id
where b.status = "DONE" group by u.user_id having sum(b.price) >= 700000 order by total_sales
고양이와 개는 몇 마리 있을까
select animal_type, count(animal_id)
from animal_ins group by animal_type order by animal_type
동명 동물 수 찾기
select name, count(name) from animal_ins group by name having count(name) > 1 order by name
년, 월, 성별 별 상품 구매 회원 수 구하기
재밌는 문제.
첫번째 풀이는 다음과 같았다. 그런데 통과를 하지 못했다.
select extract(YEAR from o.sales_date) "year",
extract(month from o.sales_date) "month",
u.gender "gender",
count(distinct u.user_id) users
from online_sale o join user_info u on o.user_id = u.user_id
where u.gender is not null
group by "year", "month", "gender"
order by "year", "month", "gender"
문제는 결국, 저 따옴표였다... 따옴표를 포함하면 어떤 이유에선지 구분이 잘 안 되고, 오히려 따옴표 없이 하니까 잘 됐다.
결론은, 따옴표고 뭐고 간에 그냥 GROUP BY랑 ORDER BY 해줄 때는 별칭 쓰지 말자.
입양 시각 구하기(1)
select extract(hour from datetime), count(*)
from animal_outs where extract(hour from datetime) between 9 and 19
group by extract(hour from datetime) order by extract(hour from datetime)
입양 시각 구하기(2)
set 함수 등을 사용하면 됨. 일단은 그냥 넘어가는 걸로,
가격대 별 상품 개수 구하기
이것도 하나의 테크닉으로 보인다. floor 함수를 써서 가격대 구간을 나누는 것.
select floor(price/10000)*10000 price_group, count(*) products
from product group by floor(price/10000)*10000 order by floor(price/10000)*10000
조건에 맞는 사원 정보 조회하기
새로운 테크닉 - 세 개 이상의 테이블 join 시키기.
with score_table as (select emp_no, sum(score) total_score from hr_grade group by emp_no),
max_score_table as (select max(total_score) max_score from score_table)
select s.total_score score, s.emp_no, h.emp_name, h.position, h.email
from score_table s join max_score_table m on m.max_score = s.total_score
join hr_employees h on s.emp_no = h.emp_no
연간 평가점수에 해당하는 평가 등급 및 성과급 조회하기
with avg_grade as (select emp_no, sum(score)/2 score from hr_grade group by emp_no),
grades as (select emp_no, case when score >= 96 then 'S' when score >= 90 then 'A' when score >= 80 then 'B' else 'C' end grade, case when score >= 96 then 0.20 when score >= 90 then 0.15 when score >= 80 then 0.10 else 0.0 end bonus from avg_grade)
select g.emp_no, h.emp_name, g.grade grade, g.bonus * h.sal bonus from grades g join hr_employees h on g.emp_no = h.emp_no
order by g.emp_no
부서별 평균 연봉 조회하기
with avg_sals as (select dept_id, round(sum(sal)/count(sal)) avg_sal from hr_employees group by dept_id)
select a.dept_id, h.dept_name_en, a.avg_sal avg_sal from avg_sals a join hr_department h on a.dept_id = h.dept_id
order by a.avg_sal desc
노선별 평균 역 사이 거리 조회하기
avg 집계 함수 유용히 쓰자. 그리고 str 붙이고 싶으면 concat 시전해주면 됨.
select route, concat(round(sum(d_between_dist), 1),'km') total_distance, concat(round(avg(d_between_dist), 2),'km') average_distance
from subway_distance group by route order by sum(d_between_dist) desc
물고기 종류 별 잡은 수 구하기
select count(*) fish_count, fish_name from fish_name_info n join fish_info i on i.fish_type = n.fish_type
group by fish_name order by count(*) desc
월별 잡은 물고기 수 구하기
select count(*) fish_count, extract(month from time) month from fish_info group by extract(month from time)
order by extract(month from time)
특정 조건을 만족하는 물고기별 수와 최대 길이 구하기
with new_fish_info as
(select fish_type, case when length is null then 10 else length end length from fish_info)
select count(*) fish_count, max(length) max_length, fish_type
from new_fish_info group by fish_type having avg(length) >= 33
order by fish_type'알고리즘 SQL 문제풀이' 카테고리의 다른 글
| [SQL] 프로그래머스 고득점 kit - JOIN (0) | 2025.01.07 |
|---|---|
| [SQL] 프로그래머스 고득점 kit - IS NULL (0) | 2025.01.04 |
| [SQL] 프로그래머스 고득점 kit - select 관련 (1) | 2024.12.27 |
| [알고리즘] 충돌위험 찾기, 가장 많이 받은 선물, 도넛과 막대 그래프 (1) | 2024.12.26 |
| [알고리즘] 동영상 재생기, 퍼즐 게임 챌린지, 충돌위험 찾기 (0) | 2024.12.23 |