[SQLD] SQL 스킬을 업그레이드하자! - 자격증은 덤이지

과목 I - 데이터 모델링의 이해 🧠
데이터 모델링의 목적
유연성, 일관성 유지, 중복 제거
데이터 모델링이란?
'현실 세계'를 단순화하여 표현하는 기법.
추상화: 상위 개념화. 데이터 모델에서 중요한 정보만 남기고, 나머지 세부사항을 제거하는 과정.
=> ERD에서 엔티티 간의 관계를 일반화할 때 사용.
=> "운전하는 법"을 배울 때, 차종별 차이를 생략하는것.
단순화: 추상화보다 더 실용적이고 직관적인 개선 과정.
=> 정규화 진행, 릴레이션의 복잡성을 줄이기 위해 테이블 병합 혹은 분할.
=> 자동차 기능 중 창문 연다처럼 쉽게 설명하는 것.
명확화: 데이터를 사용할 사람들이 같은 의미로 해석할 수 있도록 용어와 관계를 정리하는 것.
데이터 모델링의 3단계
1 개념적 모델링: ERD Entity-Relationship Diagram 사용, 엔티티와 관계 정의
2 논리적 모델링: 정규화 Normalization, 속성 정의
3 물리적 모델링: 실제 DB 스키마 설계 (테이블, 인덱스, 키 등)
데이터 스키마
DB의 논리적 구조와 제약조건을 정의함
외부 스키마: 사용자가 보는 관점
개념 스키마: 전체 데이터의 논리적 구조
내부 스키마: 물리적인 저장 구조
※ 논리적 독립성: 개념 변경 => 외부 스키마 영향 X
물리적 독립성: 내부 변경 => 외부, 개념 스키마 영향 X
Entity 용어들
Entity: 저장할 데이터의 객체 - 고객, 주문, 제품
Strong Entity: 강한 엔티티 - 독립적으로 존재 가능. ex) 학생
Weak Entity: 다른 엔티티가 존재해야만 의미 있음. ex) 학생의 성적
Entity-Relationship Diagram 작성 순서
엔티티 도출 - 배치 -
관계 설정 - 관계명 기입 - 관계 참여도(1:1, 1:M 등) 기입 - 관계 필수/선택 여부 기입
Entity의 3가지 분류
엔티티의 존재 형태에 대한 분류

엔티티의 발생 시점에 따른 분류

※ 영어 대문자 활용, 단수 명사로 표현, 의미상 중복 X
속성
더 이상 쪼개지지 않는 레벨.




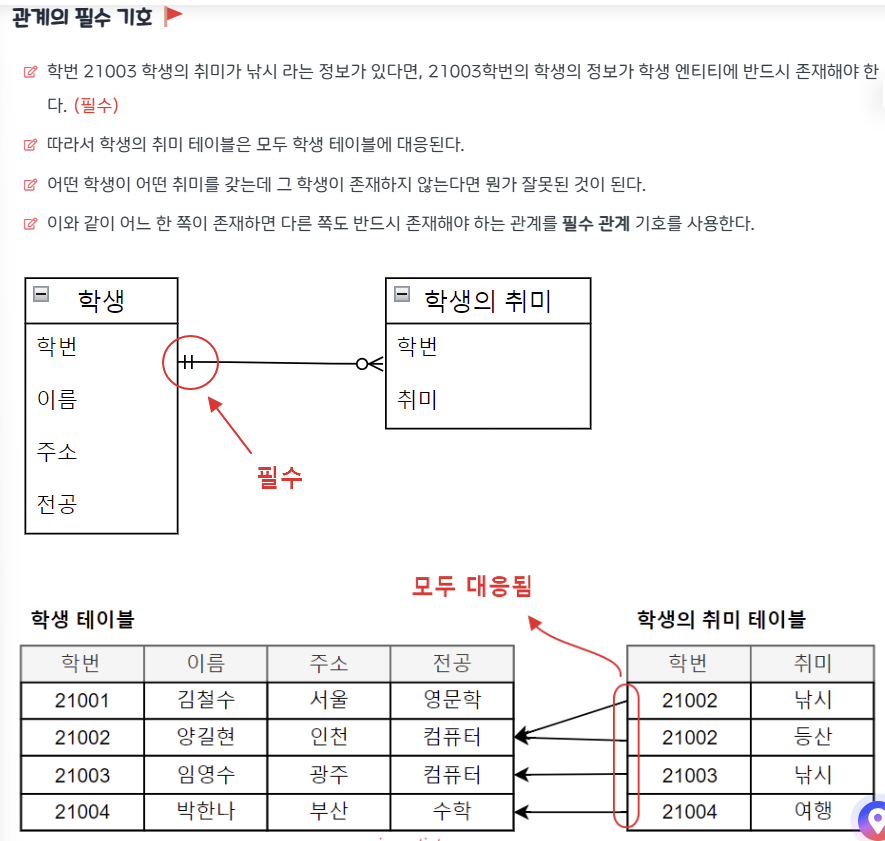
관계





성능 개선을 위한 데이터 모델링에 대하여
사전에 성능 모델링을 할수록 성능 향상을 위한 비용이 적게 듦.
분석/설계 단계에서의 성능을 미리 고려해 데이터 모델링을 수행하면 재업무 비용 최소화 가능.
성능 데이터 모델링 고려 순서
1 정규화 > 2 DB 용량 산정 > 3 트랜잭션의 유형 파악 후 반정규화 > 4 용량에 따라 반정규화 등.
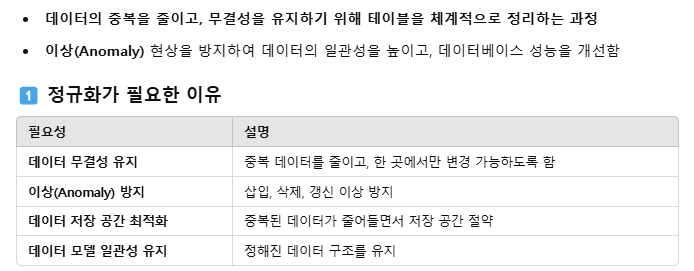
정규화
기본적으로는, 중복되는 값을 최소화하고 데이터 무결성을 유지하도록 하는 기술

제 1 정규화 1NF: 모든 속성이 원자값을 가져야 함. 중복 컬럼을 제거함. - 한칸에 하나의 데이터만 들어가야 함.
= 원자성
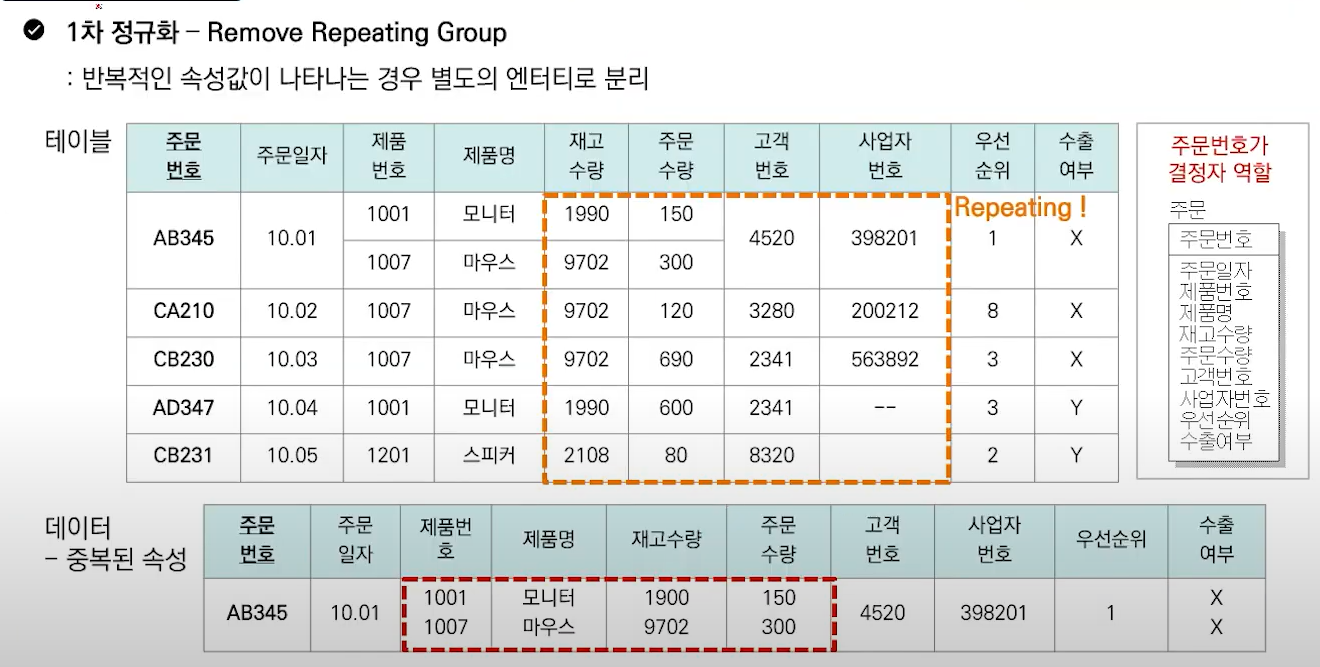
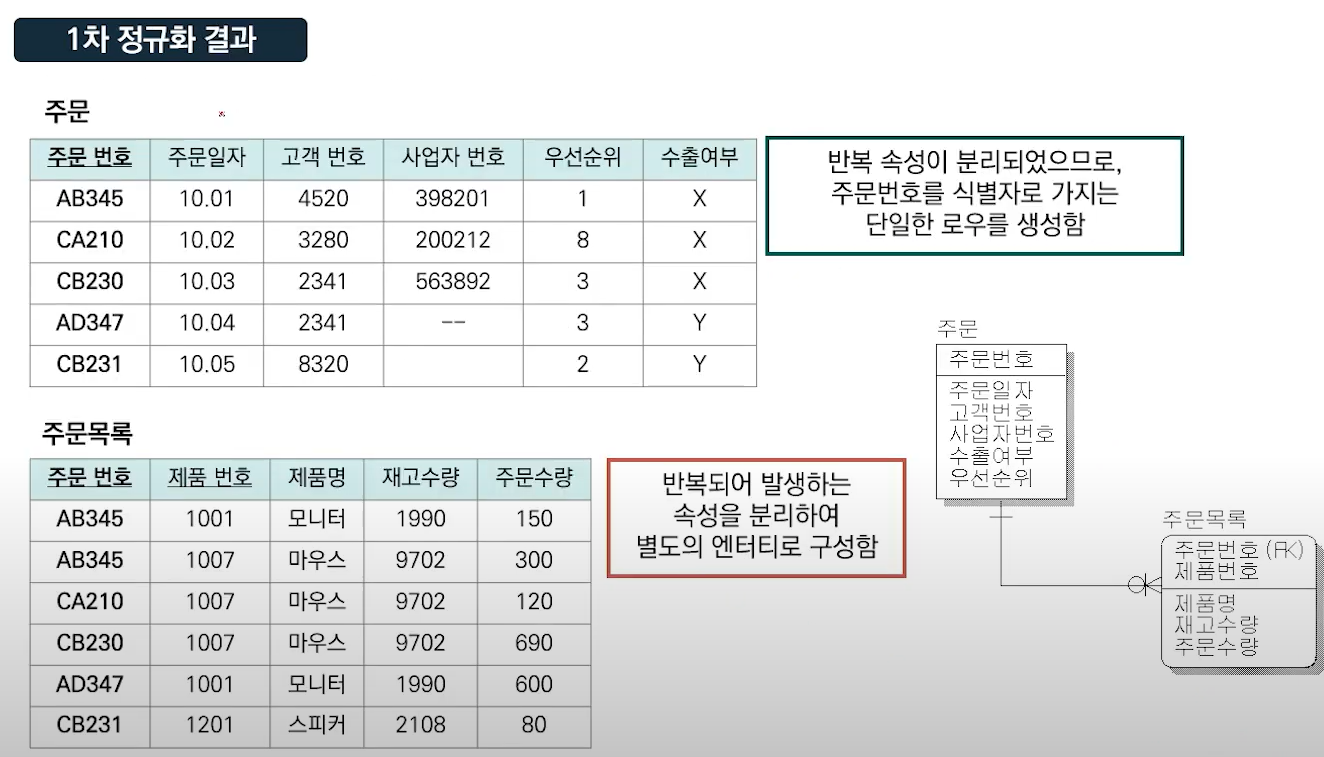
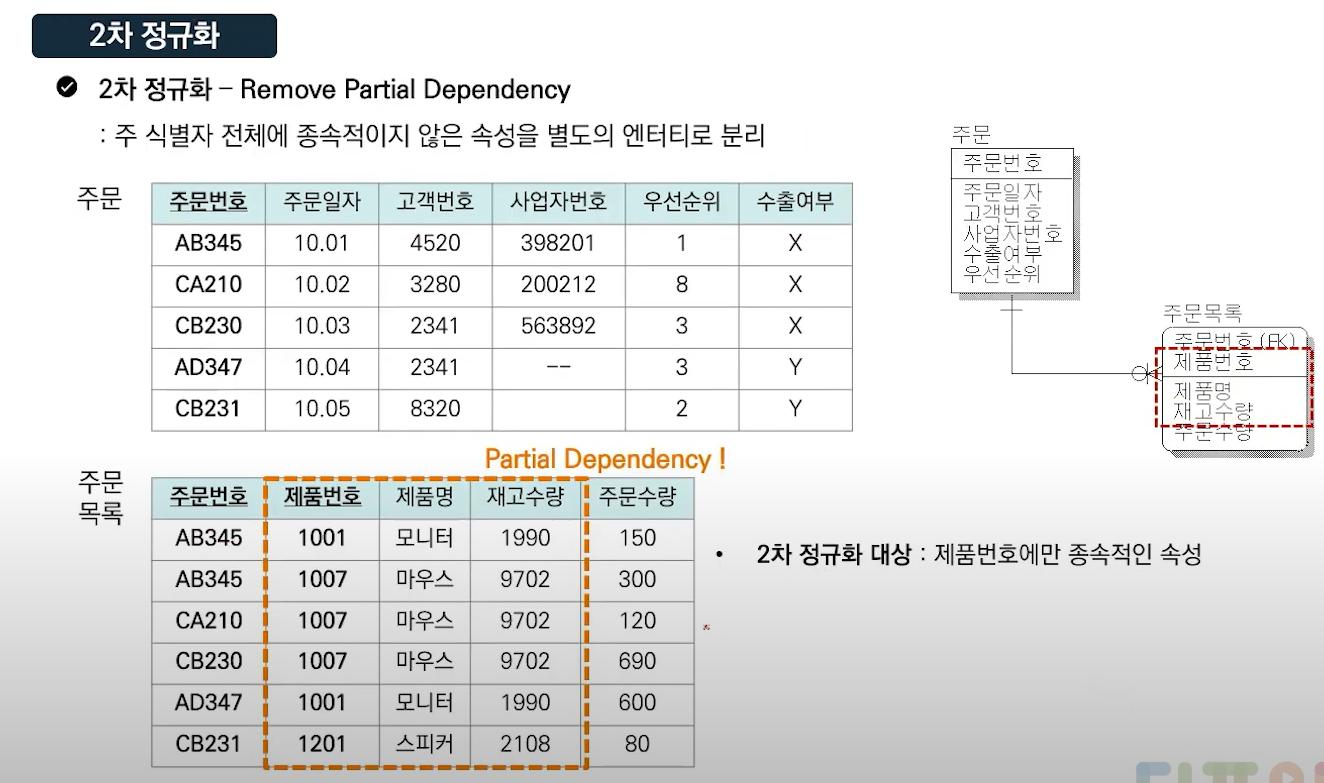
제 2 정규화 2NF: 기본키의 일부에만 종속적인 속성을 별도의 엔티티로 분리 (부분적 함수 종속 제거)

제 3 정규 3NF: 이전 종속 제거.

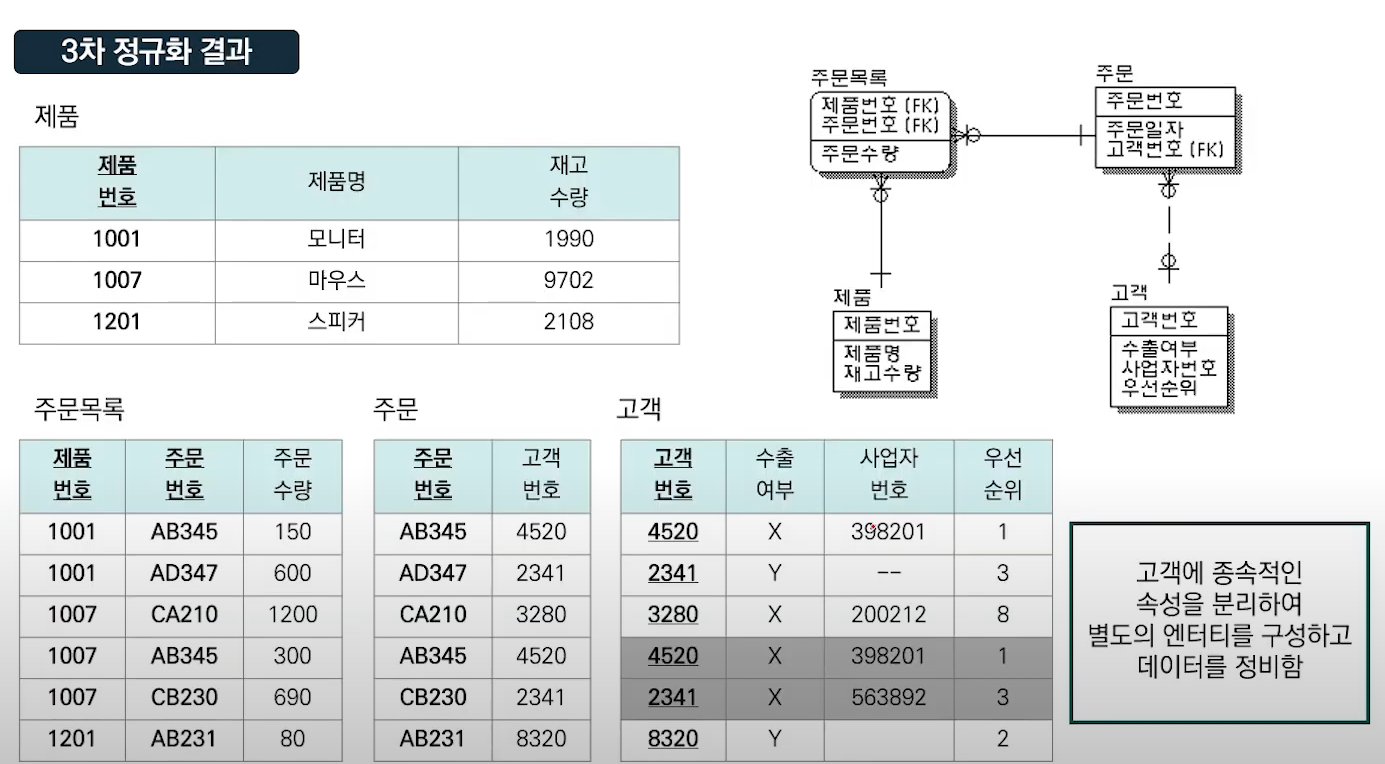
BCNF
모든 결정자가 후보키가 되도록 개선.
<정규화 전반에 대하여>
장점: 데이터 무결성, 중복 최소화 - C, U, D 에 대해 장점을 가짐.
단점: 조인이 많아질 수 있어 읽기 성능 저하 가능성 - R 에 대해 장점을 가짐.
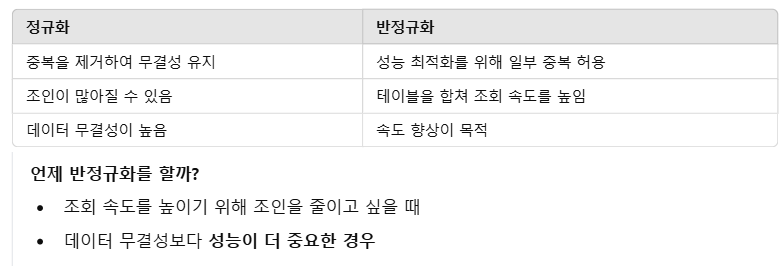
반정규화
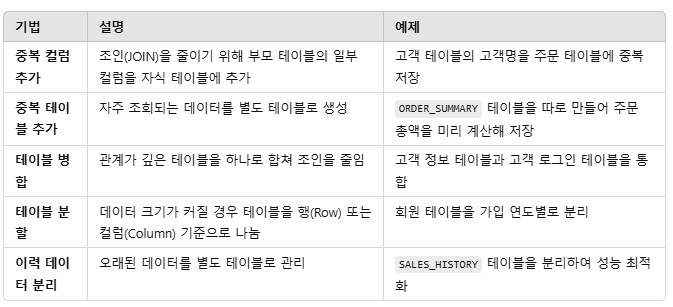
=> 중복 컬럼 혹은 테이블을 추가하든, 테이블을 병합/분리하는 등의 기법들이 있음.
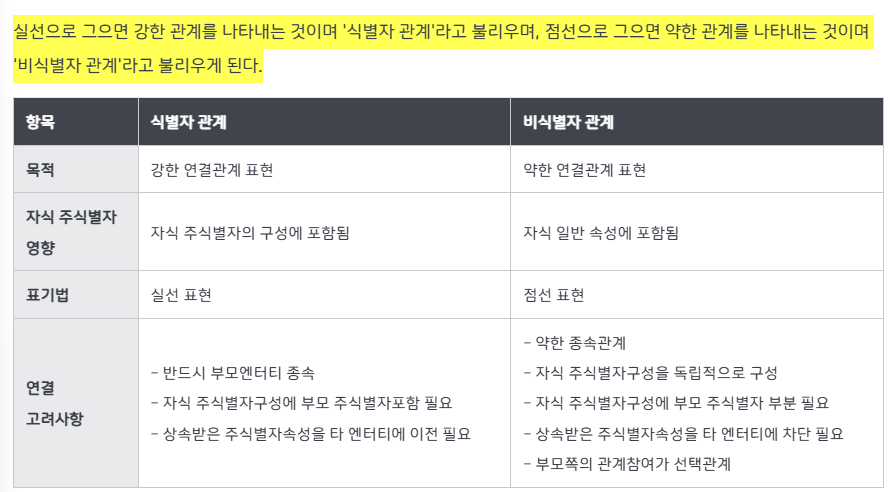
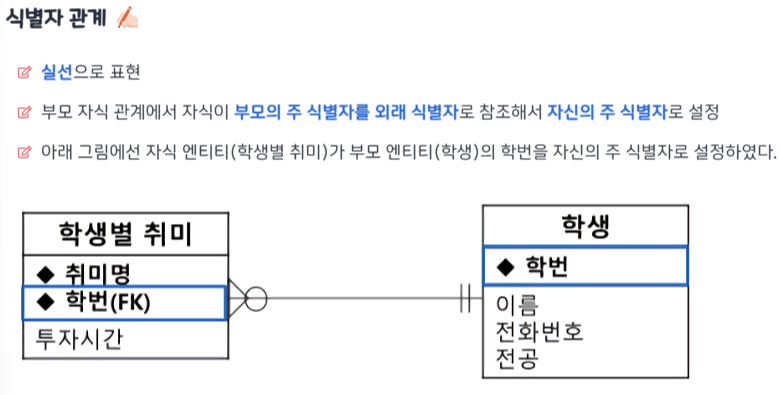
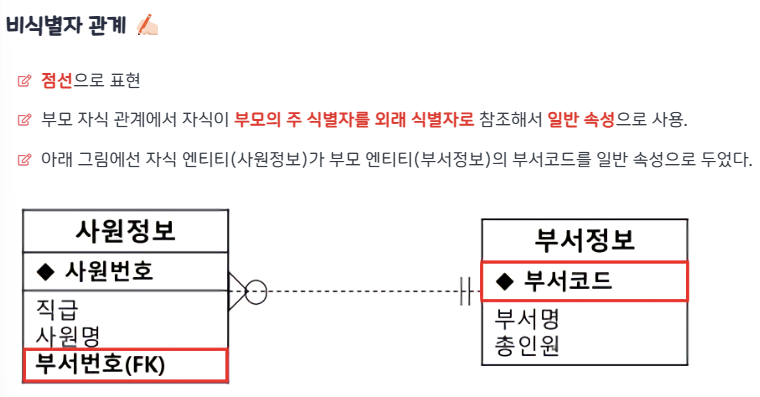
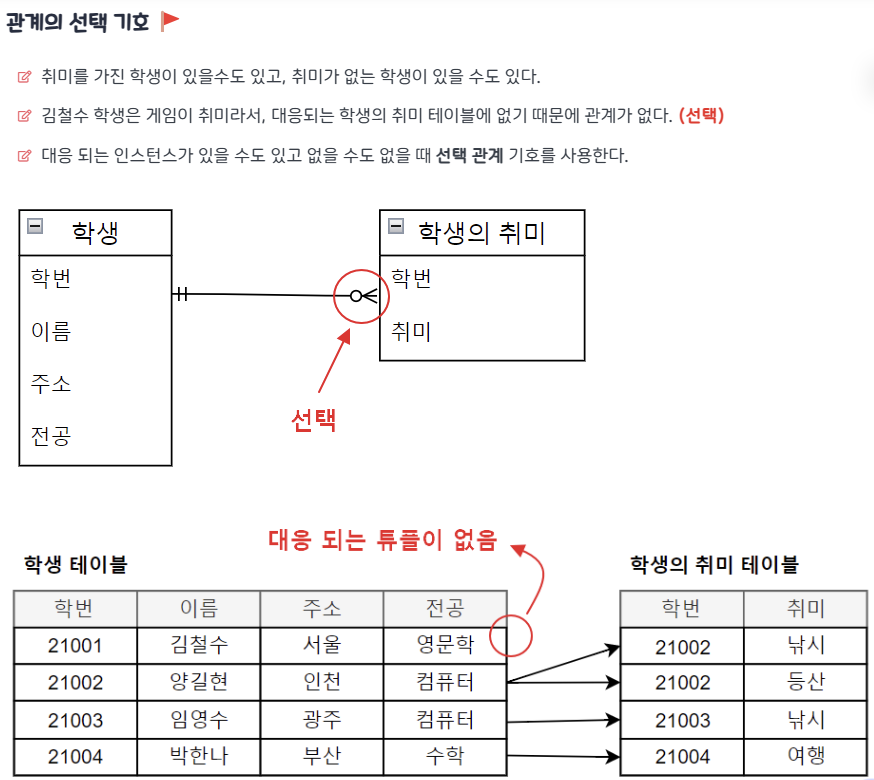
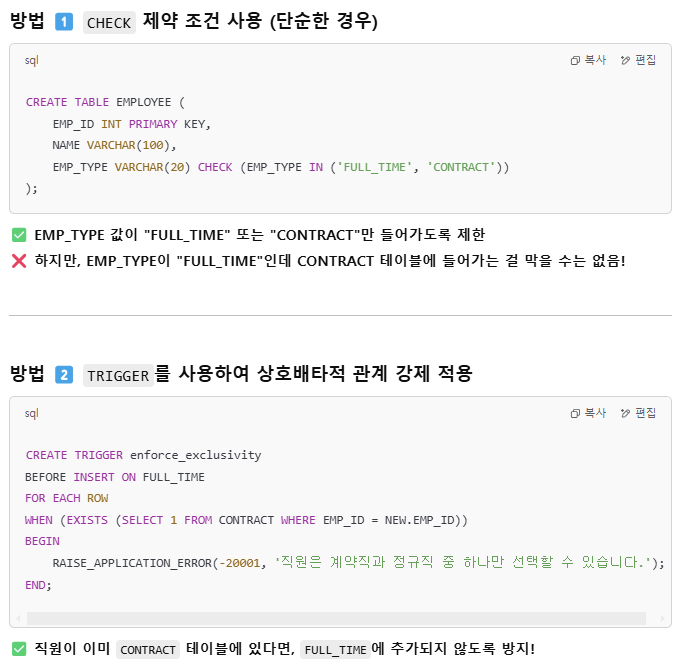
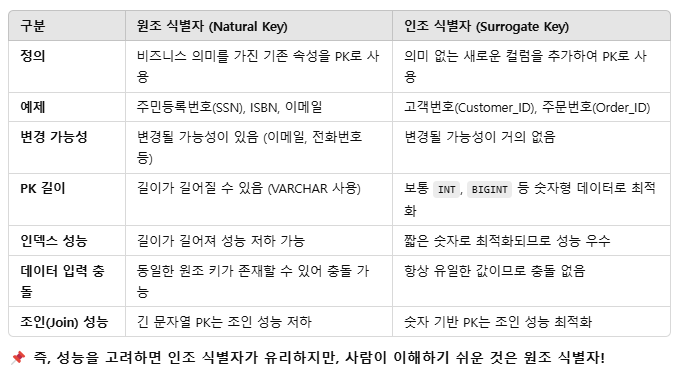
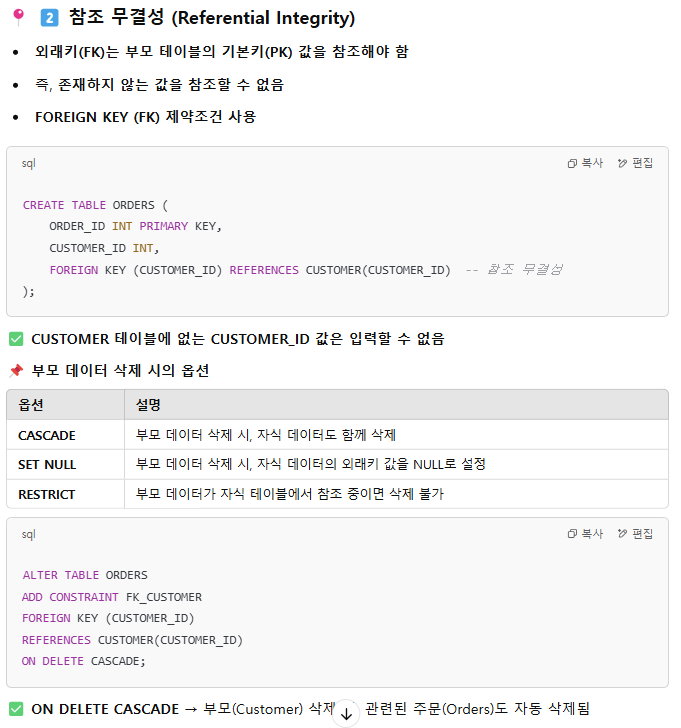
식별자 & 무결성 제약조건 - 개참도
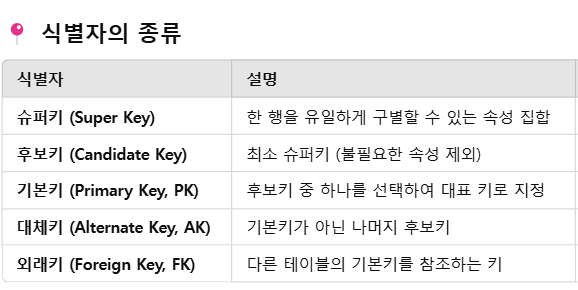

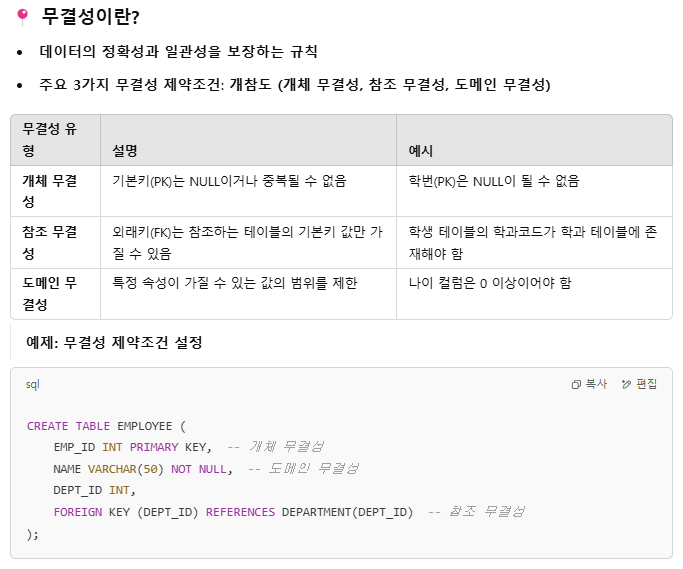
그니까 개체 무결성은 PK에 대해, 참조 무결성은 FK에 대해, 도메인 무결성은 속성의 범위에 대한 규칙.



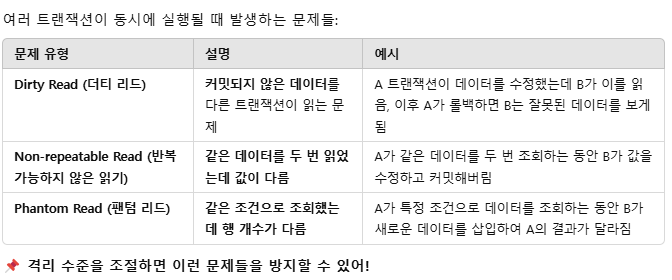
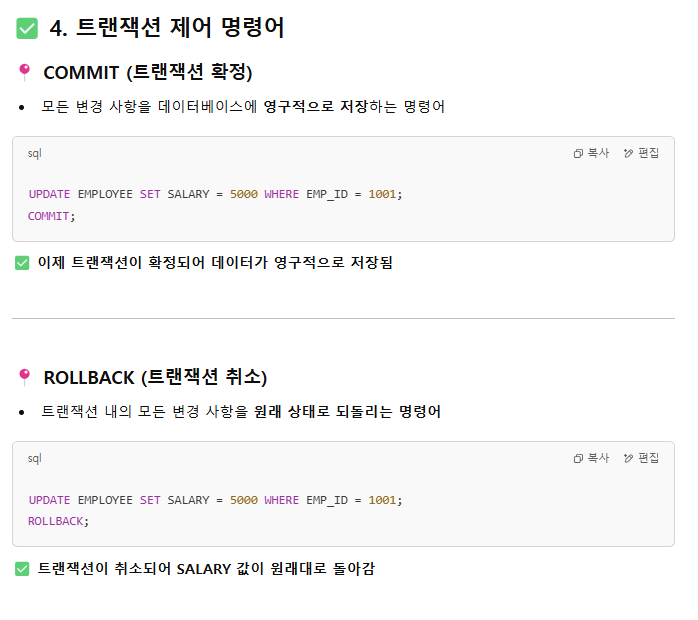
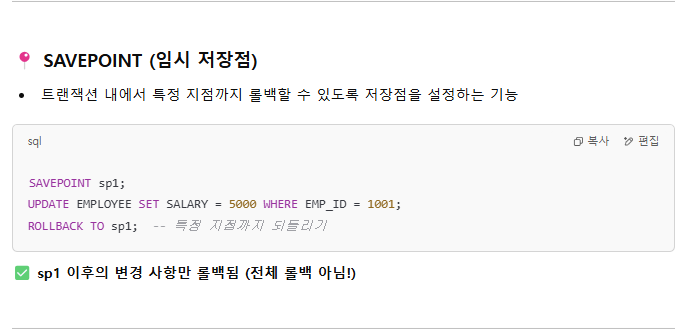
트랜잭션 관련
과목 I 완벽하게 만들기
과목 II - SQL 기본 및 활용


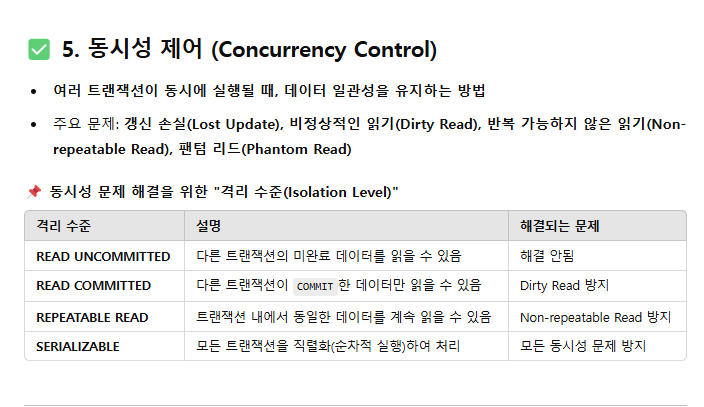
계층형 질의란?
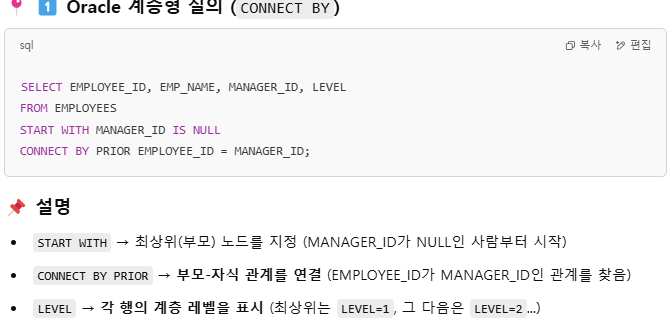
예제


※ 참고로 order siblings by,,, 이거는 같은 레벨의 경우 정렬을 이렇게 해라~ 라는 구문임.
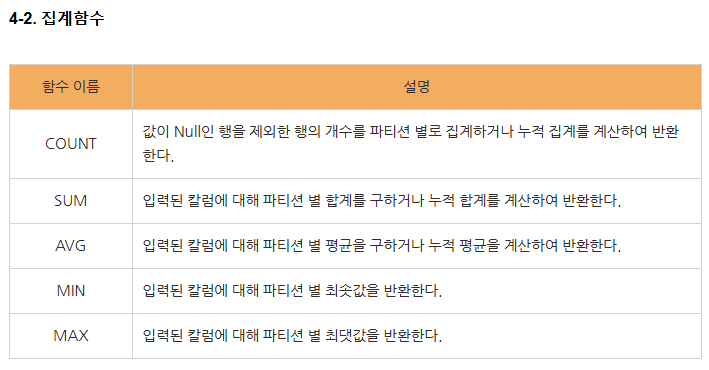
윈도우 함수들
왜 쓰지 윈도우 함수를?
* 한마디로, group by 없이도 개별 행을 유지하면서 집계함수 수행이 가능하기 때문에 그러함. - 윈도우 내에서 수행하기 때문에 가능함.
* OVER를 활용하여 윈도우 내에서 연산 수행함.

자주 쓰는 윈도우 함수

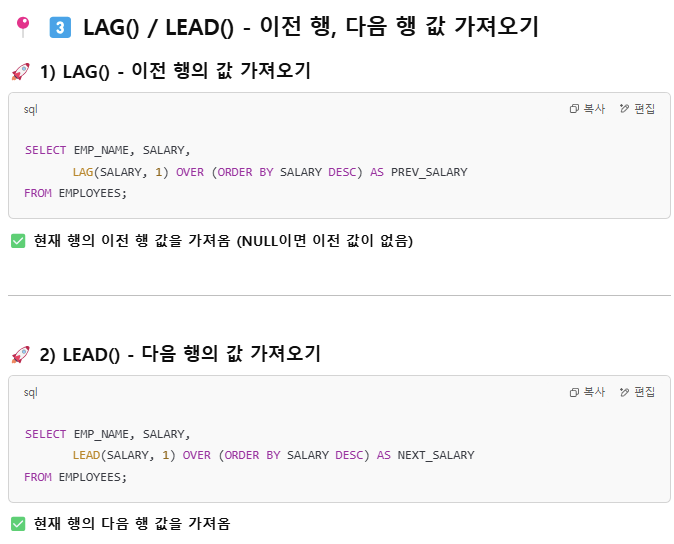
피봇 pivot?
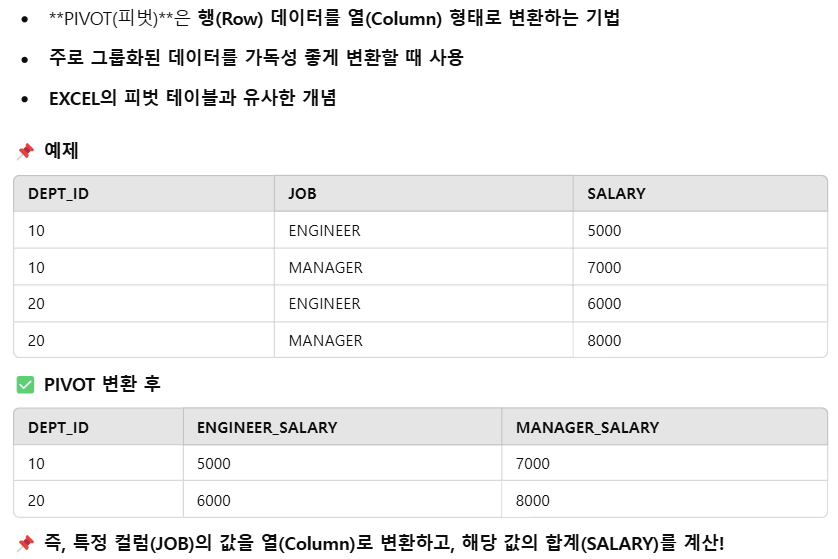


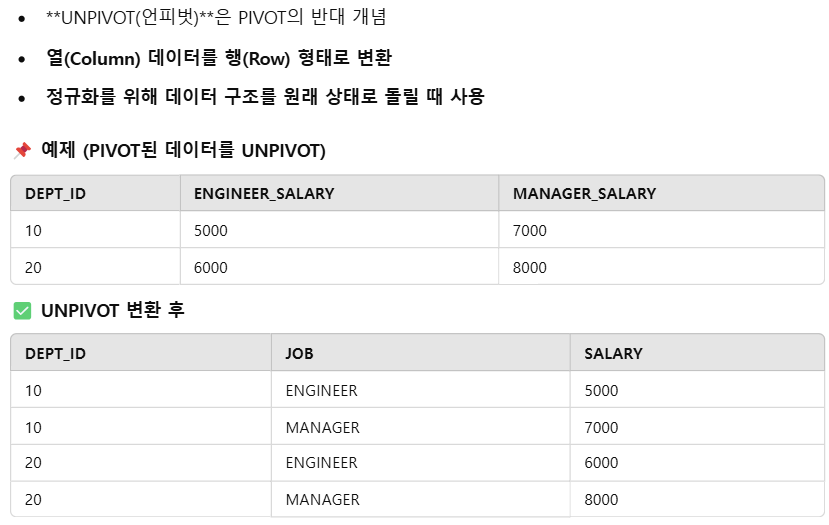


* 끄적이는 용이므로 참고만 하기 바람.