DAG 작성 기본 틀
DAG를 짜보자. DAG를 정의하는 기본적인 형태는 아래와 같음.
with DAG('user_processing', start_date=datetime(2023,1,1),
schedule_interval='@daily', catchup=False) as dag: None
with A as B: B라는 변수명에 A를 안전하게 할당하고 싶을 때 사용하는 python 문법이라고 함 - context manager.
파라미터에 들어가는 건, 유일한 이름이어야 하는 이름과, 시작일자, 인터벌 주기, catchup 변수.
이제 저 None 자리에 저 DAG에 해당되는 task들을 넣어주면 된다.
기본적으로 하나의 task는 하나의 operator에 할당하고, 하나의 목적만을 할당해야 함.
서로 다른 목적의 task를 넣으면 병렬화가 불가능할 뿐 아니라, 하나가 잘못되면 전체를 다시 실행해야 하므로.
task에 쓸 수 있는 operator들의 종류를 몇개 살펴보면,
1 action operator: function을 operate하는 execute 작업 진행함.
2 transfer operator: data를 이동시키는 역할을 함.
3 sensors: 조건에 맞을 때까지 기다리는 역할을 함.
그리고, airflow를 외부의 다른 프로그램들과 연결시킬 때는, provider를 활용한다.
이런 provider들을 쓰기 위해서는 pip install을 활용한다. 예를 들어,
snowflake를 쓰기 위해서는 pip install apache-airflow-providers-snowflake
aws를 쓰기 위해서는 pip install apache-airflow-providers-amazon 이런식으로.
airflow를 다운받을 때 pip install apache-airflow로 다운받은 것을 생각하면 됨.
Action Operator 예시
(1)
예를 들어 postgreSQL에 대한 쿼리를 task를 시키는 걸 짜본다고 하면,
1 우선 airflow 화면의 Admin 아래 들어가서, "+" 누르고 해당하는 connection 추가해주면 됨.
connection id, connection type 등 설정해주고 연결만 해주면 그만임.
2 그리고 위에서 쓴 connection id를 포함해서 아래의 코드를 작성해주면 됨.
task id, connection id, sql 코드 이렇게.
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
with DAG('user_processing', start_date=datetime(2023,1,1),
schedule_interval='@daily', catchup=False) as dag:
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='postgres',
sql='''CREATE TABLE IF NOT EXISTS users (
firstname TEXT NOT NULL,
lastname TEXT NOT NULL,
country TEXT NOT NULL,
username TEXT NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL);
'''
)
오케이, 이렇게 dag를 만들고 그 안에 task까지 만들었으면, 이제 잘 만들어졌는지, airflow에서 인식이 잘 되는지 확인.
docker-compose ps
docker exec -it <scheduler name> /bin/bash
airflow task test <DAG name> <task name> <과거의 날짜>
[ctrl + D]
docker-compose ps: 현재 실행 중인 컨테이너 목록을 확인하는 명령어.
docker exec -it: 실행 중인 컨테이너 중 특정한 컨테이너 내부에 들어가는 명령어 (우리 경우 스케줄러 컨테이너).
그 안에 들어가서, airflow task test를 통해 우리가 만든 개별 태스크를 테스트해보는 명령어.
control + D는 해당 컨테이너 밖으로 나가되, 컨테이너를 종료하지는 않는 명령어.
(2)
위의 postgresOperator 말고도, httpOperator를 쓰려고 함. 우선 코드는 이렇게 될텐데.
extract_user = SimpleHttpOperator(
task_id='extract_user',
http_conn_id='user_api',
endpoint='api/',
method='GET',
response_filter=lambda response: json.loads(response.text),
log_response=True
)
기본적으로 SimpleHttpOperator는 응답을 XCom에 저장함.
XCom이 뭐지?
response_filter: 기본 text 형태인 응답을 json 형태로 바꾸어 XCom에 저장.
log_response: API 응답을 Airflow 로그에 출력
이 코드 뿐 아니라, postgres의 경우에는 딸린 DB를 쓰는 것이므로 언제든 available하다는 걸 알 수 있지만, http 같은 경우에는 외부 시스템의 응답 여부를 확인해야 하기 때문에 sensor를 써서 확인을 해줘야 한다. 아래에서 확인.
(3)
그리고, 가져온 데이터를 처리하는 과정을 넣으려고 한다. 이번엔 python operator를 쓴다. task는
process_user = PythonOperator(
task_id='process_user',
python_callable=_process_user
)
그리고 python_callable에 들어가는 함수를 DAG보다 이전에 정의해준다.
def _process_user(ti):
user = ti.xcom_pull(task_ids="extract_user")
user = user['results'][0]
processed_user = pd.json_normalize({
'firstname': user['name']['first'],
'lastname': user['name']['last'],
'country': user['location']['country'],
'username': user['login']['username'],
'password': user['login']['password'],
'email': user['email']
})
processed_user.to_csv('/tmp/processed_user.csv', index=None, header=False)
xom_pull에 저장된 유저 데이터를 task_ids의 결과물로 도출.
json_normalize가 뭐냐면, json 형태에서 pandas 데이터프레임 형태로 바꿔주는 것!
이렇게 하면, 이전의 extract_user 태스크에서 가져온 데이터를 user로 받아서 형태에 맞춘 다음, csv 파일에 넣어줌.
Sensor 예시
Sensor라는 것은 그러니까, 특정 조건이 충족될 때까지 DAG 실행을 대기시키는 특별한 Operator.
파일, API 응답, DB 값 등 외부 이벤트를 감지하고, 조건이 충족될 때까지 task 실행을 지연하는 역할.
poke-interval: 얼마에 한번씩 조건 충족 여부를 확인할 건지 - 기본 60초.
timeout: 언제까지 센서를 유지시킬 건지 - 기본 7일.
from airflow.provider.http.sensors.http import HttpSensor
...
is_api_available = HttpSensor(
task_id='is_api_available',
http_conn_id='user_api',
endpoint='api/'
)
Dependency Injection

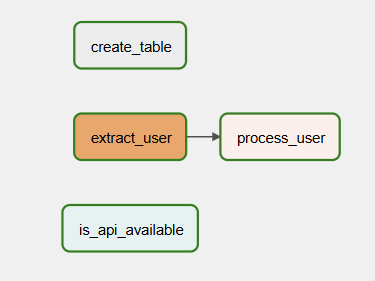
trigger로 돌려보니까 Gantt 그래프가 위와같이 나온다.
흐름상 extract_user 이후에 process_user가 진행되어야 한다. API로 값들을 fetch 해와서 거기서 나온 값들을 처리해야 하니까. 그러나 현재는 의존관계가 없기 때문에 process_user가 활성화될 일이 없다.
graph 뷰를 보면,

이렇게 되어있음. 이때 흐름에 맞게, extract_user 이후에 process_user가 실행되게끔 하기 위해서
extract_user -> process_user를 만들어주는 방법은, DAG로 돌아가서 맨 마지막에 아래 코드를 추가해주면 됨.
extract_user >> process_user
그러고 다시 trigger 돌려주면, 아래와 같이 dependency도 생기고 모두 success인 것을 확인할 수 있음.
Hook?
Hook은 기본적으로 "연결"을 담당하는 컴포넌트임. Action Operator는 "실행"을 하는데, 실행을 위해서는 일단 연결이 되어야 하기 때문에, Action Operator 내부적으로 hook을 써서 연결 작업을 수행하는 경우가 많음. - 이때는 추상화가 되어있기 때문에 유저가 직접 hook을 건드릴 일은 없음.
기본적으로 airflow에서 task를 실행시키기 위해서는 Operator를 통해야 하는데, 대부분의 경우 hook이 추상화 되어있기 때문에 굳이 직접 다룰 일은 없지만, 만약 그래야 한다면, hook을 python 함수 속에 써주고, 그 함수를 pythonOperator에서 부르는 형태로 실행시켜주면 됨.
참고로 Hook의 함수로도 데이터를 처리하는 등의 기능을 쓸 수 있음. 그러나 아까 말했듯 pythonOperator의 형태를 빌려야 airflow에서 실행 가능함.
위의 작업에서 이어져서, api로 extract하고 처리까지 한 데이터를 이제 초기에 만든 테이블에 집어넣을 시간이다.
task는 아래와 같음.
store_user = PythonOperator(
task_id='store_user',
python_callable=_store_user
)
저기에 쓰이는 _store_user는 다음과 같음.
def _store_user():
hook = PostgresHook(postgres_conn_id='postgres')
hook.copy_expert(
sql="COPY users FROM stdin WITH DELIMITER as ','",
filename='/tmp/processed_user.csv'
)
저기서 _store_user는 그냥 사용자 정의 함수고, PostgresHook이 hook의 일종임.
이렇게 하고나서 dependency 맞춰주고 refresh 해주면, ta-da!

- 의도치 않은 삽질 -
열심히 코드 쓰고 있는데, 문제가 발생했다. docker-compose ps 해봤는데 아무것도 안 뜸.

docker-compose ps는 그걸 쓰는 디렉토리에 위치한 docker-compose.yaml 파일과 연관된 컨테이너들이 떠야 함.
그런데 아무것도 안 뜸.
그래서 docker ps 해보니까 airflow 각 컴포넌트를 이루는 컨테이너 여러개가 뜸.

그렇다면 현재 돌고 있는 컨테이너들이 지금의 docker-compose.yaml 파일과 관계없다는 뜻.
그래서 현재 실행 중인 컨테이너들이 우리의 docker-compose.yaml과 연결되어 있는지 확인해 봄. 관계 없음.
결과적으로 그냥, vscode에서 새로운 터미널을 열었는데 이게 열려있는 workspace 기준이 아닌, 느닷없는 마운트 경로를 기본 경로로 사용해서 거기로 간 것. 그냥 cd로 대탈출 성공.
DAG 잘 돌아갔는지 결과물 CLI로 확인
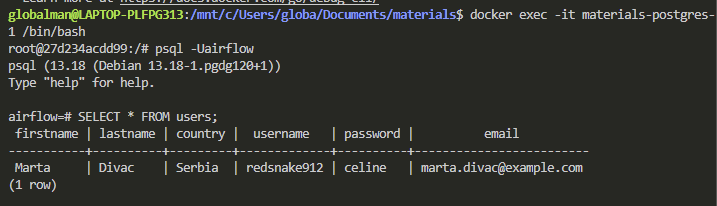
CLI로 DAG 결과물을 확인해보자. 흐름대로라면, 우리의 postgreSQL DB에 유저의 값이 들어가 있어야 함.
우선 우리의 postgre 이름을 docker-compose ps로 알아내고

그 이름대로 docker exec -it 해서 들어가서 psql -Uairflow 해서 접근한 뒤,
SELECT 문을 써서 우리가 만든 user 테이블의 값을 받아왔더니 아래와 같음. Hurray! 👏👏👏
Backfilling
Backfilling이란 과거의 DAG run을 재실행하는 것을 의미함. 이미 지나간 일정에 대해 DAG을 실행하여 데이터 처리를 보완하거나 누락된 작업을 채우는 것.
예를 들어, DAG가 1월 1일부터 매일 실행되도록 설정되어 있지만, 1/5부터 Airflow를 가동했다면, 원칙적으로는 1/1 ~ 1/4의 기간 동안 가동이 되었어야 하므로, 원하면 이를 수행하게끔 할 수 있음.
자동 Backfilling은 DAG의 python 파일에서 설정하면 됨.
DAG(,,, catchup=True)
수동 Backfilling은 python 파일이 아니라, 커맨드로 실행해줘야 함.
airflow dags backfill -s <start_date> -e <end_date> <dag_id>
번외로, 혼자 궁금한 점
❓저 태스크들 사이에 의존관계가 저렇게 1자가 되어야 하나?
꼭 필요한 의존관계만 설정하고 나머지는 병렬로 두는 게 더 효율적이지 않을까?
is_api_available >> extract_user >> process_user >> store_user
create_table >> store_user
막상 나눠보니 많이 병렬화가 되는 건 아니지만, 조금이라도 더 효율적으로 하려면 이렇게 나눠도 되지 않을까?
❗응 그래도 됨. 문제될 것 없음.
❓저 ETL 과정에서 XCom, csv 이렇게 메모리가 아닌 추가적인 매개들을 활용하는데, 보통 저렇게 진행하나?
API로부터 값 가져와서 최종적으로 postgre에 넣으면 되는 거고, 그 사이 구현 방식은 다양할 수 있을 거 같아서.
특히나 저렇게, 임시로만 쓰이는 파일들을 만들면 보통 코딩에서는 공간복잡도도 늘어나고, 나중에 제거도 해줘야 하잖아.
배치는 어차피 주기적으로 되니까 또 쓰일 거니까 제거 안해도 상관없나?
❗일단, ETL 과정에서 나오는 임시데이터들을 저장하는 방식은 여러가지가 있음.
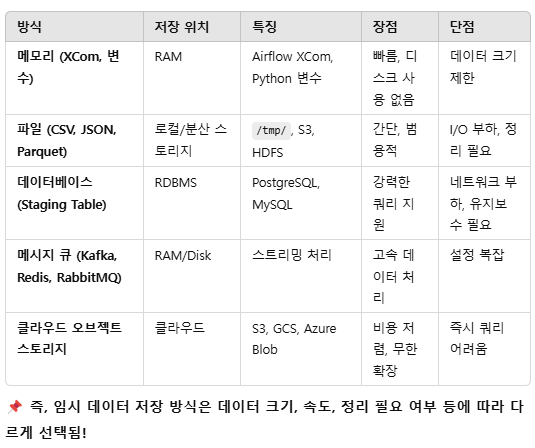
Airflow의 XCom의 경우, 자체적으로 RAM을 써서 보관하기 때문에 빠르지만, 데이터 크기가 48KB로 매우 제한적.
간단한 메타데이터, json 파일 저장하기는 좋음.
파일시스템은 데이터 크기 제한 없고 범용적이지만, I/O 부하가 발생함. 이게 퍼포먼스에 영향을 줌.
DB를 staging table로 쓰는 것도 물론 가능. SQL로 데이터 처리 가능하지만 네트워크 부하 발생.
메시지 큐는 인프라만 잘 돼있다면 베스트. 대용량 고속 데이터를 실시간으로 처리 가능. 주로 실시간 흐름에서 활용.
클라우스 스토리지는, 확장성 좋고 데이터 정리 정책 가능. 그러나 즉시 설정이 어려움. 장기 저장용으로 많이 쓰임.
'데이터 엔지니어링' 카테고리의 다른 글
| [Airflow] 닉값 못하는 실행자와, 그 단짝 데이터베이스 (0) | 2025.02.02 |
|---|---|
| [Airflow] 증기기관에 필적하는 dataset에 대하여 (inter-DAG) (0) | 2025.02.01 |
| [Airflow] Airflow UI에 대한 간단한 정리 (1) | 2025.01.30 |
| [Airflow] airflow 띄워보기 with/without 도커! (0) | 2025.01.30 |
| [Airflow] Airflow가 뭘까-요? (1) | 2025.01.30 |



