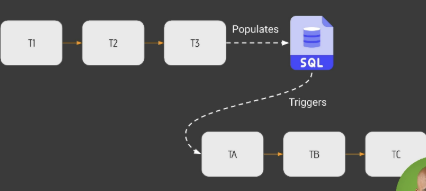
(1) 이런식으로 T 1,2,3이 끝나고 SQL이 업데이트되면, 그 값을 T A,B,C가 받아야 하는 상황이라면, SQL과 TA 사이에 Trigger Operator, Sensor를 활용해서 이를 트리거 하는 방법이 일반적이었음. 그러나 이게 좀 여러모로 복잡하고 어려움. 이걸 쉽게 할수 있게 해주는 녀석이 있다.

(2) 또한 이 일련의 흐름에서 하나의 DAG에 각기 다른 팀이 2개씩 맡아야한다고 하면, 서로 여러가지 부분에서 상충될 여지가 있다. 그렇기 때문에 하나의 큰 DAG이 아닌, 세개의 micropipeline으로 세분화하면 좋은데, 이 작업을 쉽게 할 수 있게 하는 녀석이 있다.
DATASET
dataset은 2.4 버전에 도입된 개념으로, DAG 간의 의존성을 쉽게 관리할 수 있게 하는 기능임.
기존에는 DAG 간 데이터를 주고받으려면 XCom, TriggerDagRunOperator, ExternalTaskSensor 등을 사용했지만, Dataset을 이용하면 더 직관적으로 DAG 간의 연결을 설정할 수 있음.
즉, Dataset을 이용하면 DAG 실행 결과를 데이터 형태로 저장하고, 이를 다른 DAG이 감지하여 자동 실행할 수 있음.
dataset은 그러니까, file, sql table처럼 데이터의 묶음을 말함. URI라는 주소와, EXTRA라는 나머지 정보들로 이뤄짐.
from airflow import Dataset
my_file = Dataset(
"s3://dataset/file.csv",
extra={'owner': 'james'}
)
URI는 해당 dataset에 대한 유일한 식별자로, ASCII로만 이뤄져야 하고 case sensitive함.
그리고 airflow:// 이런식으로 airflow 스키마는 쓸 수 없다고 함.
DAG을 만드는 최신 방식
우선 큰틀에서는, 두개의 DAG을 만들 거고, producer DAG가 consumer DAG 를 트리거하는 방식으로 만들 것임.
producer DAG을 아래와 같이 짬.
from airflow import DAG, Dataset
# Dataset이란 것 추가
from airflow.decorators import task
# task는 python operator 도입을 쉽게끔 도와주는 녀석.
from datetime import date, datetime
my_file = Dataset("/tmp/my_file.txt")
with DAG(
dag_id="producer",
schedule="@daily", # schedule-interval 대신 schedule 사용.
start_date=datetime(2025,1,1),
catchup=False
):
@task(outlets=[my_file])
def update_dataset():
with open(my_file.uri, "a+") as f:
f.write("producer update")
update_dataset()
consumer DAG는
from airflow import DAG, Dataset
from airflow.decorators import task
from datetime import datetime
my_file = Dataset("/tmp/my_file.txt")
with DAG(
dag_id="consumer",
schedule=[my_file],
start_date=datetime(2025,1,1),
catchup=False
):
@task
def read_dataset():
with open(my_file.uri, "r") as f:
print(f.read())
read_dataset()
이렇게 설정해두면, dataset을 producer가 바꾸는 그 자체만으로 consumer가 인지하고 바로 실행할 수 있게 함. 기존의 특정한 시각 혹은 시간의 단위가 아니라, 인과에 의해 실행되는 것이 가능해진 것임.
그리고 이 과정에서 schedule-interval이 아닌 schedule로 파라미터 이름이 바뀌고, dataset을 받을 수 있게 됨!
Dataset 활용법을 정리하면
dataset은, DAG 끼리의 의존성 문제를 수월하게 해결하기 위해 만든 개념. 원래는 producer와 consumer 사이에 sensor와 operator로 복잡한 관계를 만들어야만 하고, 그렇게 되면 이후 수정 혹은 확장하기가 안 좋았음. 그러나 airflow 2.4 버전부터는, dataset이 등장하면서, 위의 복잡한 작업 대신 dataset만으로 의존성을 정립할 수 있음.
(1) producer와 consumer에서 dataset으로 사용할 녀석을 사전에 uri로 맞춰두고, 코드 상단에 정의함.
(2) producer의 outlet에 [dataset 이름] 넣어주고
(3) consumer의 schedule에 [dataset 이름] 넣어주면 됨. 참 쉽쥬? 👏👏👏
Dataset의 한계
- DAG과 같은 airflow 인스턴스에 위치한 dataset만 사용할 수 있음.
- Consumer DAGs는 Producer에서 dataset이 수정완료된 경우 무조건 trigger 됨. dataset이 잘 수정됐는지 확인 안함.
- Producer DAG에 task 1, 2가 모두 하나의 dataset을 가리킨다면, 둘 중 하나만 수정돼도 Consumer trigger 됨.
- 외부 툴이 dataset을 수정해도 Consumer는 이를 포착하지 못함.
과정에서 그냥 궁금해진 점
dataset이 매개가 되는 그 과정이 더 자세히 알고싶다.
❓예를 들어, outlet에 dataset 이름 넣고 해당 task에서는 막상 dataset은 수정을 안 하면 어떻게 되는거지? 그래도 trigger가 되나?
❗YES. dataset의 내용에 대해서는 Consumer가 확인 안함. 그냥 해당 dataset을 참고하는 producer의 task가 완료되면 consumer가 실행되는 것임.
❓dataset이 적용되는 것은 DAG 중에서 일부 task라고 한다면, 해당 task가 끝나는 시점에 trigger가 발생해서 consumer DAG의 해당 task가 실행되는 건지, 아니면 producer DAG는 다 끝이 나야 consumer DAG가 실행되는건지?
❗YES. Producer DAG의 해당 task만 완료되면, Consumer DAG 전체가 실행됨. Producer DAG의 다른 task들은 신경 안 쓰고, 또 Consumer DAG의 해당 task만 실행되는 게 아니라 전체가 된다는 점.
❓@task 어노테이션을 붙이면 해당하는 함수를 실행하는 라인을 꼭 작성해야 작동되는 것인지?
❗YES. task 어노테이션은 이게 task다 라는 의미일 뿐, 해당 라인을 실행하는 파트를 꼭 적어줘야함.
❓/tmp 폴더가 자주 보이던데, 무엇이고 어떤 의미가 있는지?
❗/tmp 폴더는 임시 파일을 저장하는 디렉토리. XCom이 일반적으로 한 DAG 내부에서만 공유되고, 데이터 한도가 적다는 것을 타파하는 좋은 대안.
주의해야할 점은, 시스템 재부팅 시 파일 삭제된다는 점. 그러니까 일시적으로 쓰이는 녀석들만 활용하면 됨. XCom은 메타데이터 DB 이므로 자체적으로 휘발이 되지는 않음.
그리고 worker마다 /tmp가 지칭하는 폴더가 다를 수 있다고 함.

'데이터 엔지니어링' 카테고리의 다른 글
| [Airflow] 진화론, SubDAG을 지나 TaskGroups까지! (intra-DAG) (0) | 2025.02.02 |
|---|---|
| [Airflow] 닉값 못하는 실행자와, 그 단짝 데이터베이스 (0) | 2025.02.02 |
| [Airflow] 비로소, DAG 작성하고 테스트해보기 (0) | 2025.01.31 |
| [Airflow] Airflow UI에 대한 간단한 정리 (0) | 2025.01.30 |
| [Airflow] airflow 띄워보기 with/without 도커! (0) | 2025.01.30 |



