OSI 7 계층의 가장 상단에 위치하여, 유저와 직접 맞닿는 부분인 응용계층에 대해 좀 더 알아보려고 한다.
키워드는 HTTP, DNS, SSH이다.
HTTP (HyperText Transfer Protocol)
HTTP는, 웹 페이지와 기타 웹 컨텐츠를 전송하기 위한 주요 프로토콜이다. 웹 브라우저(클라이언트)와 웹 서버 간에 문서와 데이터를 교환하는 데 사용된다. HTTP는 요청/응답 프로토콜로, 사용자가 웹 브라우저를 통해 특정 웹 페이지를 요청하면, 서버는 HTTP를 통해 그 페이지를 사용자에게 전송한다.
이름에서도 알 수 있듯이, HTTP도 프로토콜, 즉 규약이다. "클라이언트가 이렇게 보내면 서버는 이렇게 답변한다" 라는 일련의 약속인 셈이다. 이 규약은 시간 별로 변천해왔다.

HTTP/1.0 – Building Extensibility (1996): 하나의 TCP - 하나의 객체
- 기능: HTTP 헤더의 도입으로 메타데이터와 컨트롤 정보를 포함할 수 있게 됨. 상태 코드와 인코딩 방식도 도입되어 에러 처리와 다양한 데이터 타입의 처리가 가능해짐.
- 제한: 매 요청마다 새로운 TCP 연결이 필요했으며, 연결 후 즉시 종료되는 비효율적인 면이 있었음.
=> 헤더가 도입되어 여러가지 데이터 타입의 처리가 가능해졌고, 상태 코드도 도입되어 에러에 대한 서버의 응답도 들을 수 있게 되었으나, 하나의 객체 당 하나의 TCP 연결을 해야 했음.
예를 들어, 동영상 컨텐츠가 용량이 커서 10개의 객체로 나뉘었다면, HTML 원본 + 동영상 객체 10개, 즉 11번의 상호작용이 필요했고, 각 상호작용마다 TCP 연결을 해줘야 했으므로 총 22번의 상호작용, 22RTT(Round Trip Time)가 필요했다는 큰 단점이 있었음.
HTTP/1.0 with Parallelization (1996): 그렇지만 여러 개 TCP 동시에
parallelization이라는 기술이 등장. 하나의 객체를 보내려면 하나의 TCP가 필요하다는 점은 동일했지만, 한 번에 여러 개의 TCP 연결을 동시에 열 수 있게 하는 기술. 이렇게 하면 한 번에 TCP 연결을 여러 개 하여 각 연결마다 하나의 객체를 보내면 결국 한 번에 여러 개의 객체를 보낼 수 있었기 때문에 시간을 단축할 수 있었음. 위의 예시라면, HTML을 위해 TCP 연결 + 객체 전송 (2RTT) 가 필요하고, 이후에 10개의 객체를 3개씩 묶어 보내면 결국 4번만에 전송이 가능하므로 (4 * (TCP 연결 + 객체들 전송)), 즉 10RTT만에 위의 전송을 완료할 수 있었음.
그러나 단점은, TCP의 연결을 동시에 너무 많이 하게 되면 서버와 네트워크에 부하를 준다는 점이었음.
HTTP/1.1 – Standardization (1997, updated 1999): 하나의 TCP - 여러 개의 객체, persistent HTTP
- 특징: 표준화된 버전으로, 이후 20여년 간 애용됨. 웹의 성장에 맞추어 성능 개선과 기능 추가가 이루어짐.
- 기능: 지속 연결(Persistent Connections), 파이프라이닝, 청크 전송, 캐시 제어, 콘텐츠 협상 등이 추가되어 네트워크 효율과 속도가 크게 향상됨.
- 제한: 파이프라이닝의 한계와 대기 시간이 문제가 됨.
=> 드디어 파이프라이닝이라는 기술이 등-장. 하나의 TCP 연결을 통해 여러 HTTP 요청을 순차적으로 보내고, 서버가 이를 순서대로 처리하여 응답하는 기술. 대역폭 자체가 보통 여러 개의 객체가 오가는 데 무리가 없기 때문에, 대역폭을 보다효율적으로 사용할 수 있음. 위의 예시의 경우, TCP 연결 + HTML 송수신 + 10개의 객체 송수신 => 총 3RTT에 가능.
그러나 단점은, 위의 설명처럼 "순차적으로" 보내야 했기 때문에, 만약 덩치가 큰 녀석이 앞쪽에 위치한다면 그 녀석 때문에 흐름에 병목현상(HOL, Head-Of-Line)이 생길 수 있었음. 수신쪽에서 순서대로 받아야 하므로 그 녀석 때문에 뒷 순서들은 도착을 잘 했는데도 인정을 못 받고 대기해야 하는 불상사가 일어나는 것.
HTTP/2 – Performance Focus (2015)
- 특징: 성능 개선에 중점을 둔 메이저 업데이트로, SPDY 프로토콜을 기반으로 개발됨.
- 기능: 바이너리 프레이밍, 멀티플렉싱, 서버 푸시, 헤더 압축 등이 도입되어 동시 다발적인 요청과 응답 처리가 가능해졌고, 대역폭 사용이 최적화됨.
- 제한: 기존의 HTTP/1.x와는 크게 다른 구조로 인해 구현의 복잡성이 증가했음.
가장 중점적으로 봐야할 특징은, 멀티플렉싱. 단일 TCP 연결을 통해 여러 개의 HTTP 요청과 응답을 동시에 처리할 수 있게 함으로써, 기존의 1.X 버전의 비효율성을 개선함. 즉, 하나의 TCP 연결에 여러 개의 객체를 전송하는 점은 위의 파이프라이닝과 같지만, (1) 그 객체의 단위가 기존의 "메시지"가 아니라 더 작은 "프레임"이고, (2) 무엇보다 여러 개의 프레임을 "동시에" 보낼 수 있게 됨. 고로 HOL을 발생하지 않게 하는 개선을 함.
HTTP/3 – Next Generation (개발 중)
- 특징: UDP 기반의 QUIC 프로토콜을 사용하여 TCP의 일부 제한을 극복하려는 시도.
- 기능: 연결 설정 시간의 단축, 향상된 오류 복구, 멀티플렉싱의 개선 등을 목표로 하고 있음.
- 제한: 아직 개발 중이며, 널리 채택되기까지는 시간과 노력이 필요함.
최근 HTTP 사용의 세계적인 추세
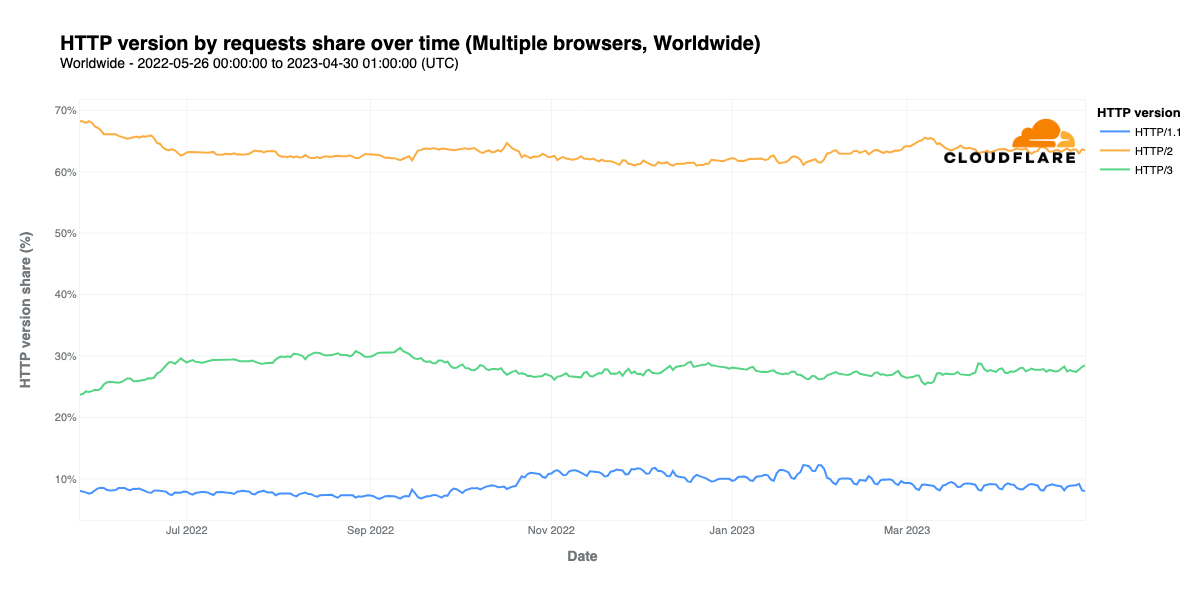
HTTP 1.1은 대략 10%, 3은 대략 30%, 그리고 2가 대략 6~70%로 과반을 차지하고 있음.
빈번히 발생하는 HTTP 에러코드들

- 응답 상태 코드가 (2**)인 경우, 성공적인 응답(successful responses) 의미.
- 응답 상태 코드가 (4**)인 경우, 클라이언트 오류(client errors) 의미.
- 응답 상태 코드가 (5**)인 경우, 서버 오류(server errors) 의미.
더 자세히는,
- 400 Bad Request (잘못된 요청): 클라이언트의 요청이 서버에 의해 이해되지 않았을 때 발생. 주로 요청 구문이 잘못된 경우에 이 에러 코드가 반환.
- 401 Unauthorized (인증되지 않음): 요청이 해당 리소스에 대한 유효한 인증 자격 증명이 없기 때문에 적용되지 않음.
- 403 Forbidden (금지됨): 서버가 요청을 이해했으나 승인을 거부.
- 404 Not Found (찾을 수 없음): 서버가 요청받은 리소스를 찾을 수 없음. 일반적으로 URL이 잘못되었을 때.
- 500 Internal Server Error (내부 서버 오류): 서버가 예상치 못한 상황을 만나 요청을 수행할 수 없을 때.
- 502 Bad Gateway (잘못된 게이트웨이): 서버가 게이트웨이나 프록시 역할을 하면서 상위 서버로부터 유효하지 않은 응답을 받았을 때.
- 503 Service Unavailable (서비스 이용 불가): 서버가 요청을 처리할 준비가 되어 있지 않습니다. 대개 서버 과부하나 유지보수.
- 504 Gateway Timeout (게이트웨이 시간 초과): 서버가 게이트웨이 또는 프록시 역할을 하며 상위 서버로부터 시간 내에 응답을 받지 못했을 때.
DNS (Domain Name Server)
간단히 말하면, 인터넷의 주소록 역할. 우리가 쓰는 일반적인 도메인 이름 (예를 들어 www.example.com) 을 브라우저에 입력하면, DNS는 이 도메인 이름을 IP 주소 (예를 들어 192.168.1.1) 로 변환함. 그러니까, 도메인 - IP 주소 쌍을 만드는 것임. 사람은 숫자를 기억할 필요없이 더 쉽게 인터넷 주소를 외우면 되고, 그걸 DNS를 통해 번역해서 컴퓨터가 이해하는 IP 주소로 바꿔, 컴퓨터가 알아서 처리하게 하는 방식. 전 세계의 모든 도메인 이름은 그에 맞는 IP 주소와 매치되어 있음.
그런데 전 세계에 도메인이 한두 개가 아님. 2024년 현재, 350,500,000개 정도가 존재한다고 함. 심지어 매년 4~5% 씩 증가하고. 그니까 저걸 한 곳에 두면 관리하기도 어렵고, 해킹이 들어왔을 때 취약하기도 하고(분산 데이터베이스), 한번에 여러 개의 요청이 들어오면 DNS가 처리하기도 힘들기 때문에(로드 밸런싱), 여러 군데에 분산하는 시스템을 사용 중임.
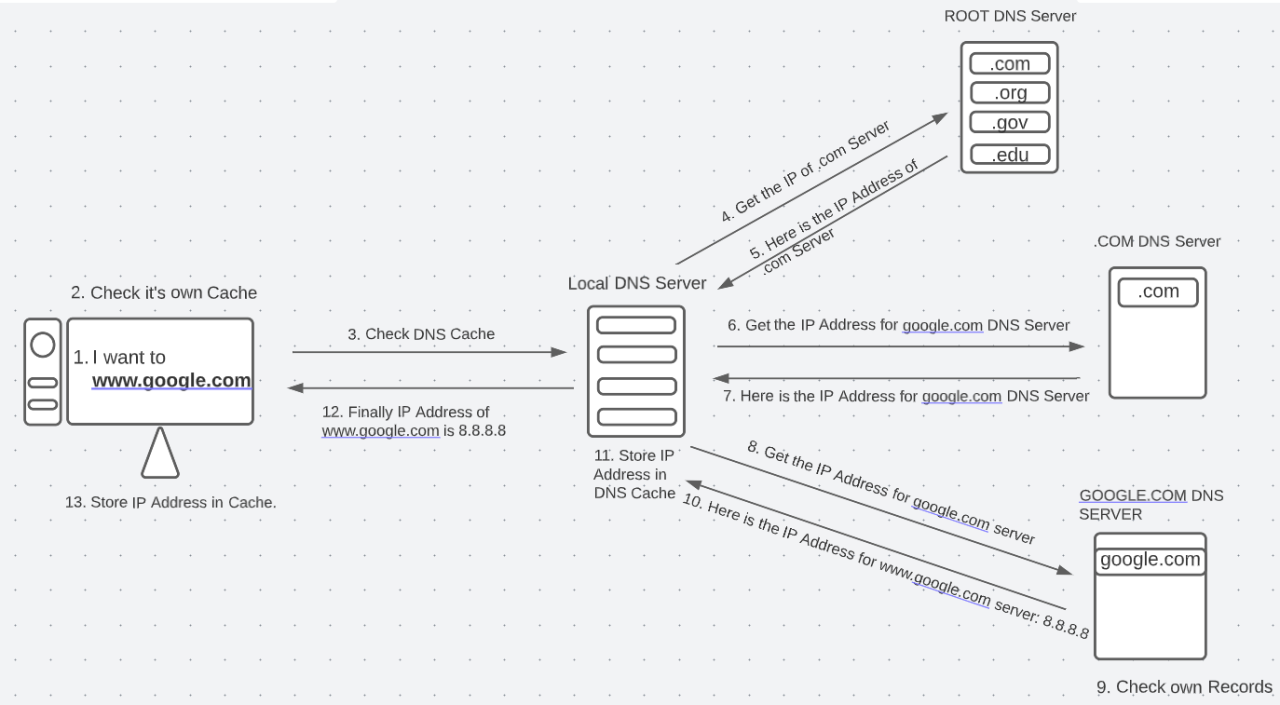
이 시스템을 탑-다운 방식으로 이해하면 너무 어려우니까, 바텀-업 방식으로 가보도록 하자. 아래의 '인터넷에 www.google.com을 치면 일어나는 일'의 DNS 조회 과정을 주목.
인터넷에 www.google.com을 치면 일어나는 일
1 브라우저 캐시 체크:
www.google.com을 치면, 이걸 번역하기 위해 DNS로 가는 것이 아니라, 그 전에 혹시나 저장해둔 정보가 있는지부터 확인함. 예를 들어 브라우저 캐시, OS 캐시, 라우터 캐시, ISP 캐시 등을 확인함. 만약 다 뒤져봤는데 정보가 없다고 하면, 비로소 DNS 조회 과정이 시작됨. DNS 조회 과정은, 도메인 이름에서 www를 제외하고 .을 기준으로 뒷 부분부터 들어감.
2 DNS 서버(caching resolver)로 IP 주소 받기:
IP 주소는 (이 경우에 google.com), 해당 도메인 네임의 authoritative Name Server에게 있음.
ISP DNS 서버는 해당 목표물의 authoritative 네임서버만 얻어내면 됨.
(1) root 서버에 .com 서버의 IP 주소를 물어보고 해당 TLD 서버(이 경우 .com) 응답 받음.
(2) TLD 서버(이 경우 .com)에 google.com의 authoritative 네임서버 IP 주소를 물어보고 응답 받음.
(3) authoritative 네임서버에 google.com의 IP 주소를 물어보고 응답 받음.
3 브라우저가 TCP/IP 프로토콜을 사용해 서버에 연결 시도
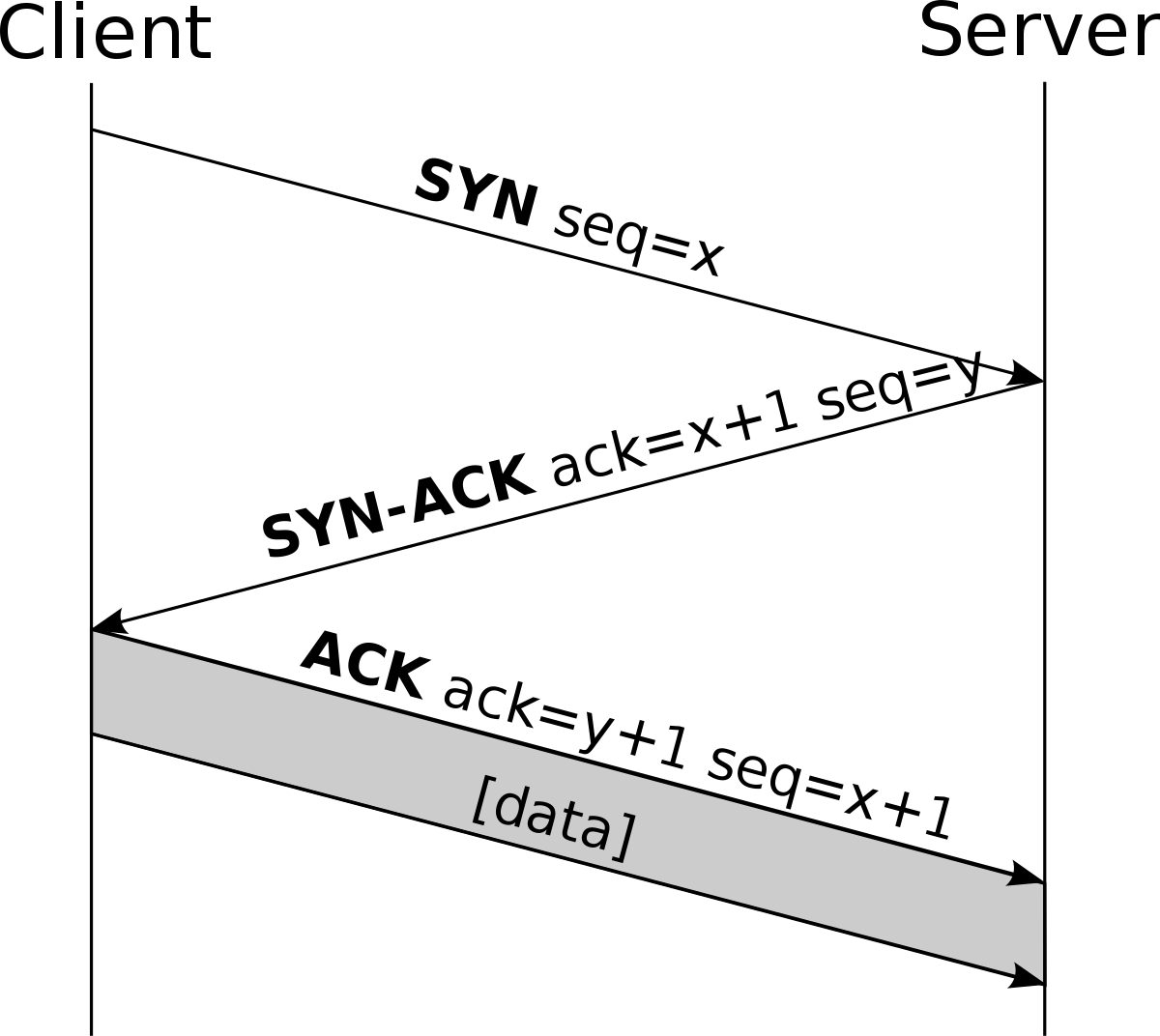
가장 먼저 전송계층에서 3-way handshake를 통해 TCP 연결을 하고, 이후에 네트워크 계층에서 라우팅을 통해 경로를 설정하고 메시지를 보냄. TCP(그리고 UDP), IP 에 대해서는 이후에 자세히 다룸.
4 Firewall & HTTPS / SSL
이렇게 TCP 연결을 시도하는 중에, 보안책을 쓰는데, 예를 들어 Firewall과 HTTPS/SSL.
FIREWALL은 해커가 엄청난 트래픽을 보내는 경우를 대비해, 특정 IP 주소에서 접근해오는 신호를 차단할 수 있음.
HTTPS/SSL은 클라이언트와 서버가 주고받는 정보를 암호화해서 정보가 새더라도 못 알아보게끔 만드는 행위.
5 Load Balancer
해당 주소 (google.com) 의 로드 밸런서가 길을 가로막고 있다가, google.com이 보유한 수많은 서버 중 트래픽이 가장 원활한 녀석을 골라서 그 녀석에게 TCP 요청을 보내줌.
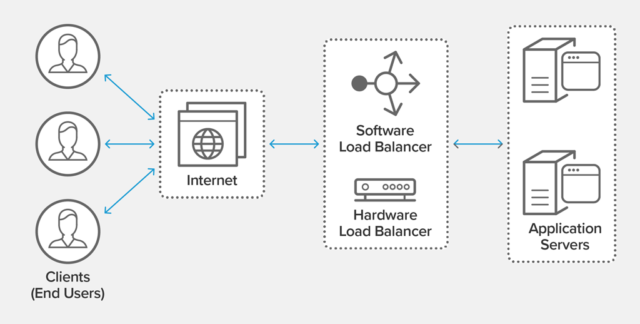
6 Web server와의 교류
TCP 연결이 된 후, 클라이언트가 요청을 보내게 됨. 그러면 서버는 그에 맞는 응답을 하게 되고, 일련의 상호작용을 하게 되는 것. 앞서 조금 다뤘듯이, TCP, IP, Ethernet(MAC) 은 각각 전송, 네트워크, 데이터 링크 계층에서 헤더로 쌓여서 전송됨. 클라이언트 단에서 응용을 떠나고 물리를 거칠 때에는 아래의 형태를 띔.
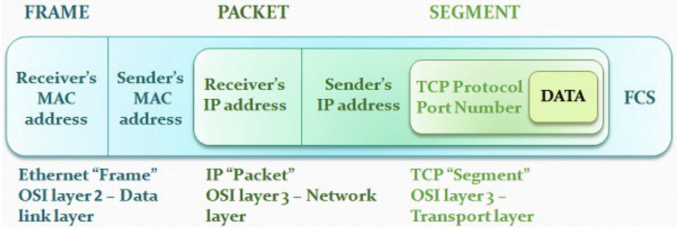
7 Web server로부터 받은 파일 HTML 컨텐츠 렌더링
브라우저가 서버에서 받은 HTML 코드를 렌더링하며, 필요한 이미지나 다른 파일들을 또 요청하게 되고, 해당 컴포넌트들이 모여서 클라이언트의 화면에 렌더링 됨.
'CS 전공수업 > 컴퓨터 네트워크' 카테고리의 다른 글
| [네트워크] 네트워크 보안 (0) | 2024.06.04 |
|---|---|
| [네트워크] TCP Congestion Control (0) | 2024.05.30 |
| [네트워크] ARQ: Stop-and-wait, Go-back-N, Selective repeat (0) | 2024.05.06 |
| [네트워크] 전송계층 - TCP와 UDP, 그리고 (De-)Multiplexing (0) | 2024.05.06 |
| [네트워크] OSI 7 계층 (vs. TCP/IP 4 계층) (0) | 2024.04.30 |



