spark에서의 aggregation은 built-in functions으로 주로 쓰임.
기본으로 아래 코드 필수임.
from pyspark.sql import functions as f
Aggregating Dataframes and Windows Functions
아래와 같이, df의 sql like 방법 혹은 sqlexpr로 sql을 직접 갖다쓰는, 두가지의 방식이 모두 가능함.

group by 도 마찬가지. sql을 갖다 쓸수도 있고, 아닐수도 있지만, 직접 갖다 안 쓸 이유를 모르겠음.

예를 들어 아래와 같은 결과물을 내고 싶다고 치자. Country와 WeekNumber를 composite key columns로 한다.

이를 SQL이 아닌 방식으로 처리하면 아래와 같은 코드가 나옴.

그러나 만약, 여기에 더불어서 아래와 같이 running total 과 같이, 그러니까 국가별로만 주별 수치를 누적하는 결과물이 필요하다고 하면, 이건 기존의 기능들로는 어려움. 이런 상황에 windows function을 활용하면 좋음.

JOIN
뭐 이쪽도 기존의 SQL과 크게 다를 것 없지만, 그 논리를 spark data frame에 맞게 표현하기만 하면 됨.

★★★ 결론: 거의 모든 데이터 처리는 SQL을 그대로 갖다쓰는 편이 좋다!


JOIN의 내부 구동: Shuffle Merge(주로 쓰임) vs. Broardcast Hash
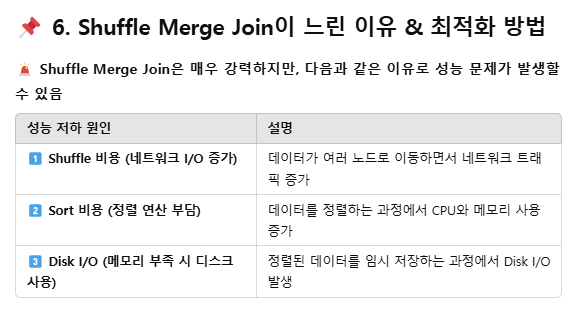
일반적으로 spark에서 데이터 처리를 할 때 가장 시간을 많이 잡아먹는 부분이 바로 이 JOIN이다.
그렇기 때문에 엔지니어로써, 이 부분을 최적화하는 것이 가장 핵심적인 역할이라고 할 수 있다.
Shuffle (Map Reduce)



Suffle 단계가 끝나면, 하나의 실행자에 서로 맞는 데이터들이 들어가기는 하지만, 정렬은 보장되지 않은 상태기 때문에, 더 빠른 join을 위해, 정렬을 확실히 시킴.
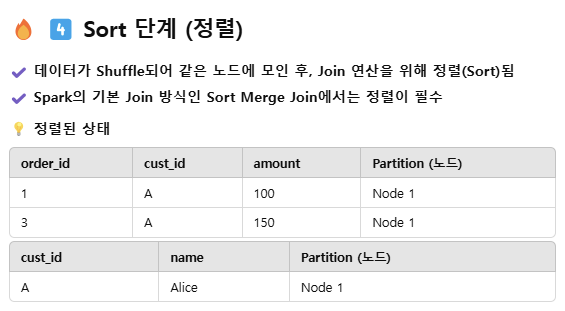

앞서서도 언급했듯, JOIN 과정은 spark 데이터 처리에 있어서 가장 병목을 야기할 가능성이 높은 과정임.
그래서 최적화가 매우 중요함. 우선 아래와 같은 항목들이 병목을 야기함.

3개짜리 partition을 가지고 shuffle 해보면 위의 결과물이 나옴.
JOIN Optimization


Broadcast join이란?
기본적으로 spark 연산은 인-메모리 형태로 진행되기 때문에, 실행자의 메모리 용량을 뛰어넘는 연산이냐 아니냐가 매우 중요한 척도다. 이때, 큰 파일과 큰 파일을 join하게 되는 것이 대표적인 메모리 용량을 뛰어넘는 연산이다. 보통 3~4 GB 정도면 large라고 판단한다. 일반적으로, Large to Large는 shuffle join, Large to Small은 broadcast join을 시전함.



결과적으로 아래과 같이 나옴.

Bucket Joins



Bucket을 활용하는 것과 Partition은 뭐가 다르지?


Bucketing 예시



그런데 자꾸만, bucketing을 통해 shuffle을 없앤다고 표현들을 하는데, 상식적으로 shuffle을 없애는 것이 아니라 최소화하는 것이 아닌가 싶었다. 그래서 확인해보니, shuffle은 그러니까, 서로 만나야 하는 아이들이 서로 다른 실행자에 위치해있다면 필수적으로 이동시켜야 하기 때문에 그 과정을 shuffle이라고 부르는 거라, bucketing을 하면 shuffle 과정이 없어지는 것이 옳은 표현이다.
* 그리고 parallel을 돌릴 때 maximum으로 진행할 수 있는 수가 얼마인지도 확인해야 함.
대표적으로, # of executors, # of shuffle partitions, # of unique id를 가진 tasks
'데이터 엔지니어링' 카테고리의 다른 글
| [데이터 엔지니어링] 데이터 웨어하우스, 레이크, 마트와 데이터 모델링 💫 (0) | 2025.02.24 |
|---|---|
| [Spark] 캡스톤 프로젝트🚧: from HIVE to Kafka (0) | 2025.02.23 |
| [Spark] Spark의 꽃🌺, Transformations (0) | 2025.02.21 |
| [Spark] Spark의 매우 도움되는 API 친구들 (0) | 2025.02.20 |
| [Spark] 본격적인 프로그래밍 on spark 🧑💻 (0) | 2025.02.19 |



