PyCharm을 활용할 것. 처음에 PySpark, PyTest 라이브러리도 설치를 해준 채로 시작해야 함.
Application Logs Log4J
Log4J를 활용해보자.

Log4J란? 로깅 프레임워크인데, Apache에서 만든 거라 spark랑 잘 맞으므로 저걸 자주 같이 씀.

각종 configuration 있는데, 일회성의 것들이므로 skip forward...
spark session의 configuration은 4가지가 있는데, 개발자로써 사용하는 건 보통 SparkConf나 spark-submit CLI 이렇게 두개임. 나중에 필요하면 그때 더 깊게 공부하면 됨.
Spark Session에 대하여
* Driver가 곧 Spark Session이라고 일단은 이해하자.
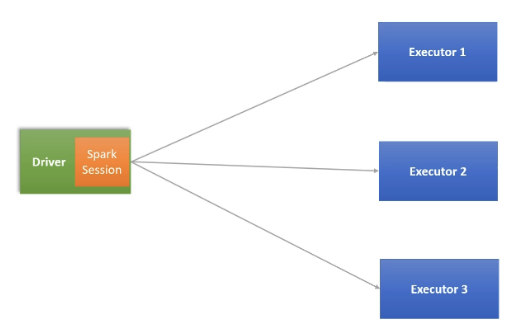
기본적으로 스파크 프로그램을 시작할 때는 아래의 코드로 spark session을 만들고 나서 시작.
싱글톤이고, 하나의 스파크 프로그램은 하나의 세션만 허용됨.
spark = SparkSession().builder.getOrCreate()
부가적인 것들을 추가해서 세션을 열고 싶다면, 아래처럼.
그러고 다 끝나면 stop으로 닫아주고.
spark = SparkSession().builder.appName("Hello Spark").master("local[3]").getOrCreate()
spark.stop()
Dataframe에 대해

이런 식으로 data 폴더 내부에 sample.csv라는 파일이 있다고 생각하자. 개발 및 디버깅용 파일임.
그런데, 코드 안에 파일 path를 넣고 싶지 않기 때문에, pycharm의 기능을 활용하여 파일을 pass 하는 걸로.
이걸 읽기 위해서는 spark.read...를 쓰면 됨. 이렇게 하면 sys를 쓰지 않고도 쓸 수 있나봄.
survey_df = spark.read.csv(sys.argv[1])
암튼 이렇게 해서 가져올 수 있는데, csv는 제대로 읽기 어렵다고 함. 그게 뭐냐면, 예를 들어 우리의 파일을 봤을 때 첫번째 줄은 헤더라서 그 아래부터의 줄과 구분이 되어야 함. 그걸 해주는 방법은 아래와 같음.
survey_df = spark.read.option("header", "true").csv(sys.argv[1])
Dataframe은 기본 schema가 정해진 것이 아니기 때문에, inferschema라는 게 있기는 한데 대부분의 경우 잘 안 먹힘 (data type 등을 유추하는 녀석). 그래서 앞으로는 infer schema 말고, define schema를 활용하는 것이 좋음(StructType 활용).
그리고 참고로, spark 코딩을 할 때 각 기능별로 모듈화 하는 것이, 당연하게도 재사용성에 좋기 때문에 이것을 생활화하는것이 좋음.
실무에서는, 로컬 디렉토리가 아니라 HDFS 혹은 amazon S3 등에 파일이 저장될 것. 이런 저장소들은 모두 분산 클러스터에 저장되어 있으므로, 하나의 파일은 수백개의 파티션으로 나뉘어 10개 이상의 노드에 나누어 담겨있음.
Partition 상태로 되어있으므로, 우선은 spark driver가 그 데이터들을 in-memory로 가져오고

이후 배정된 cluster의 노드들의 cpu 들에 각각 매치시켜서 받게끔. 이때 매칭은, 네트워크 기반 지역성에 따라 매칭됨.
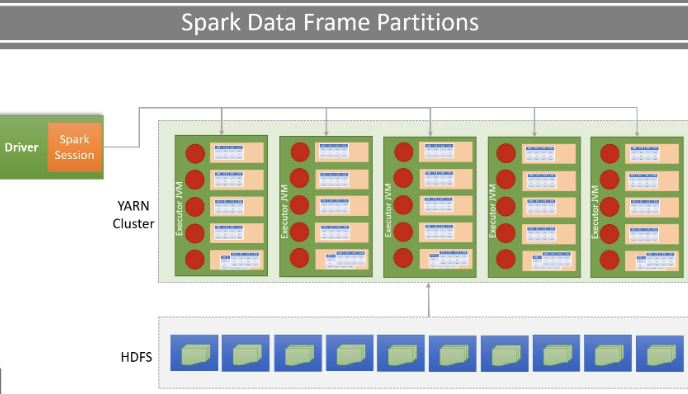
그러면 각각의 노드에서 분할된 파티션들을 처리하는 방식인 것이다. 한마디로 다시 다 합칠 필요없다는 것.
그래서 분산에 최적화되었다는 것.
※ 앞서 언급한대로 기본적으로 dataframe은 immutable이지만, 새로운 녀석을 만들고 거기에 저장해주면 됨.
Narrow Dependency vs. Wide Dependency Transformation - inside operation

한마디로, partition된 채로 적용해도 결과에 문제없는 방식이 Narrow dependency. where 등 포함.
그 외에 wide dependency는, 그렇게 했을 때 문제가 생기는, group by 같은 녀석.
이거는 도중에 한번 shuffle/sort 과정을 통해 재배치를 해줌. group by 말고도 order by, join 등.
물론 이 두가지 모두 spark가 내부적으로 알아서 함.

Spark는 시간을 거슬러,,, lazy operation
스파크는 line by line으로 서사적으로 진행하는 것이 아니라, lazy operation을 통해 최적화를 함.
transformation은 lazy, action은 immediate임.



한마디로, Action이 없으면 아무런 변화가 없다는 뜻. 어쩌면 근데 당연한 것임.
실행 플랜 - Spark Jobs, stages and tasks

왼쪽의 코드를 실행시키면, 오른쪽처럼 여러개의 job이 되고, 각각이 또 여러개의 stage가 되고, 또 각각이 여러개의 task가 되어 비로소 execution 된다.
※ 참고로 UI에서 저걸 확인하고 싶으면, UI는 런타임 시에만 전개가 되므로 input("") 이런 식으로 의도적으로 런을 계속 시켜둔 채로 확인하면 된다고 함.
예를 들어, 아래와 같은 방식으로 나뉜다고 보면 됨.


Unit Tests
예를 들어 아래와 같은 테스트 케이스가 필요하다고 치자.
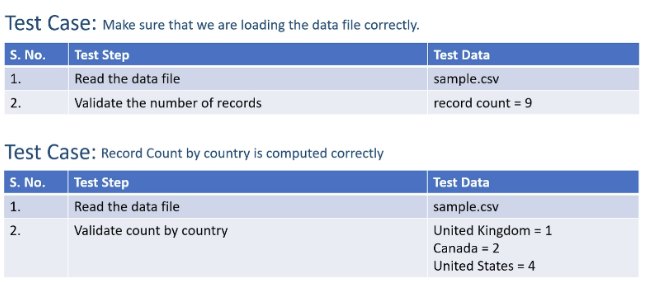
python file을 만들고 그걸로 test를 처리해주면 그만임. 아래처럼.
TestCase.unittest 가져와서 assertEqual 활용하면 됨.

지금까지의 일련의 코스를 https://www.udemy.com/course/apache-spark-programming-in-python-for-beginners/learn/lecture/20192602#content에서 리뷰 한번 하고 감.
'데이터 엔지니어링' 카테고리의 다른 글
| [Spark] Spark의 꽃🌺, Transformations (0) | 2025.02.21 |
|---|---|
| [Spark] Spark의 매우 도움되는 API 친구들 (0) | 2025.02.20 |
| [Spark] 스파크 실행 모델과 구조 (0) | 2025.02.18 |
| [Spark] Spark에서의 쌍두마차, Table 과 Data Frames (0) | 2025.02.18 |
| [Spark] Spark @ Databricks Cloud 기본 (0) | 2025.02.11 |



