DBMS, RDBMS, NoSQL
데이터들은 DB에 저장.
이 DB를 관리하는 시스템을 DBMS 즉, DataBase Management System이라고 함.
RDBMS는 데이터가 표 형태로 저장되어 고정된 스키마를 가지고 있는 형태를 뜻하고.
NoSQL은 데이터가 고정된 스키마 없이 다양한 방식으로 저장 가능 - 딕셔너리, 문서, 그래프 등.
RDBMS로는 MySQL, PostgreSQL, Oracle 등이, NoSQL로는 MongoDB (문서형) 등이 있음.
RDBMS는 수직확장(기존의 서버를 업그레이드)에 더 적합함. 수평확장 (다중 서버)은 어려움.
RDBMS에 우리가 접근하여 뭔가 인터랙션할 수 있는 언어가 SQL. NoSQL은 다 다름 - MongoDB는 MQL.
* 기본적으로는 SQL은 백엔드 DB용이지만, 프론트나 iOS, 안드로이드에서도 쓰고 싶으면 SQLite 쓰면 됨.
DB > 테이블 > 레코드 > 컬럼
DB는 테이블 단위로 나눌 수 있음. 기능 단위로, 회원 테이블, 메뉴 테이블, 게시글 테이블 등.
테이블을 이루는 단위는 레코드. 게시글 테이블이라면 1번 글, 2번 글, ... 각각이 레코드.
그리고 각각의 레코드에 대해, 작성자, 날짜, 내용 등 해당 레코드를 또 나눈 항목들이 컬럼. 메타데이터 느낌!
INDEX
컬럼을 탐색하려면, O(N)만큼의 시간이 걸리는데, 더 효율적으로 만들기 위해서 트리의 형태로 해당 컬럼을 저장해두는 것. B+TREE라는 형태의 저장법을 활용한다.
SQL 문법
(1) 질의어 (Data Query Language)
테이블에서 컬럼 가져오고 싶으면, SELECT [CustomerName] FROM [Customers]
두개 가져오고 싶으면, SELECT [CustomerName], [Address] FROM [Customers]
다 가져오고 싶으면 SELECT * FROM [Customers]
특정한 조건에 맞는 것들만 가져오고 싶으면 SELECT [Address] FROM [Customers] WHERE [Age] = 19;
WHERE을 쓸 때, RANGE 관련이 나오면 [Age] BETWEEN [x] AND [y] 이런 식으로 작성.
마찬가지로, 특정한 문자열을 포함하는지를 확인하기 위해선 WHERE [Options] LIKE %[King]% 이런 식으로 씀.
이게 중요하다. [Date] = '2022-01' 뭐 이런 식이라면, DB의 컬럼 인덱스를 활용할 수 없기 때문에 비효율적임.
컬럼의 순서대로 정렬하고 싶다면 SELECT [Name] FROM [Customers] ORDER BY [Age]
컬럼의 반대 순서대로 정렬하고 싶다면 ... ORDER BY [Age] DESC
컬럼의 정렬은 큰 흐름, 작은 흐름 순으로 적용하고 싶다면 ORDER BY [Age], [Name] DESC 이런 식으로.
새로운 컬럼을 만들고 싶으면 SELECT [Val] AS [Average_fee] FROM ...
ROUND(, 0)은 소수점에서 반올림하기, AVG()는 평균내기, LEFT(, 3)은 왼쪽에서 세개 글자, UPPER()은 대문자화.
... IS NULL 이렇게 is 도 쓸 수 있음.
몇개의 레코드만 샘플 식으로 가져오고 싶다면, LIMIT 10 이렇게 해주면 상위 10개만 나옴.
(2) 조작어 (Data Manipulation Language)
두개 이상의 테이블을 엮고 싶으면, JOIN 키워드를 활용하면 됨. INNER, FULL, LEFT, RIGHT, CROSS JOIN
하고, ON 으로 엮어주면 됨. WHERE과는 별개임. ON을 통해서 기준이 될 칼럼에 대한 정보를 저장하는 것.
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
SELECT A.column1, B.column2
FROM TableA A
FULL OUTER JOIN TableB B ON A.id = B.id;
데이터 결합, 데이터 무결성 유지, 효율적인 데이터 검색.
* COALESCE(TLNO, 'NONE'): TLNO가 None이면 'NONE' 처리하도록.
* 비트 연산도 자주 씀. 특히나 하나의 DB에서 여러 개의 버전을 만들어야 할때.
GROUP BY
SQL에서 데이터를 그룹화할 때 사용하는 명령어.
데이터를 특정 컬럼을 기준으로 그룹화하고, 집계 함수(예: COUNT(), SUM(), AVG(), MIN(), MAX() 등)를 적용 가능.
기준이 되는 녀석을 기준으로 다 GATHER한다는 뜻. HAVING으로 세부조건을 조정해줌.

만약 아래처럼 해주면, COUNT(*)에서 *가 받는 건 USER_ID와 PRODUCT_ID 의 조합.
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(*) > 1
ORDER BY USER_ID ASC, PRODUCT_ID DESC;
plus alpha parts
(2) SELECT 쿼리의 수행 순서
FROM, ON, JOIN, WHERE -> GROUP BY, HAVING -> SELECT -> DISTINCT -> ORDER BY
(3) Trigger란?
데이터베이스에서 자동적으로 호출하는 프로그램. 특정 테이블에 대한 DML 문이 수행되었을 때.
AFTER, BEFORE 등으로 후처리, 전처리 가능함.
-> 트리거를 쓰면 DB 쪽 업무가 과중화될 우려가 있어서, 어지간하면 앱단에서 처리하는 것이 더 나음.
(4) Index란?
테이블의 데이터를 효율적으로 검색하기 위해 사용되는 데이터베이스 객체.
책의 목차와 비슷한 역할을 하며, 데이터의 저장 위치를 빠르게 찾아 테이블을 FTS 할 필요 없게끔 함.
Index는 기본적으로 정렬 상태를 유지함. 인덱스는 B-Tree 구조로 구현됨.
물론 일부는 Hash를 쓰는 경우도 있고, 이때는 정렬보다는 키-값 매핑에 초점을 둠.
Index는 그러나, insert, delete, update 작업 시 인덱스도 함께 갱신되어야 하므로 추가적인 비용이 발생함.
Index는 테이블과 별도로 저장됨.
(5) 정규화란?
1 제 1 정규화: 한칸엔 하나의 데이터만!
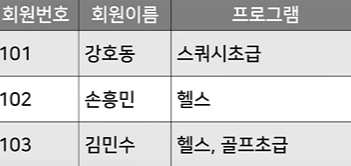
저렇게 한 칸에 하나의 데이터만!
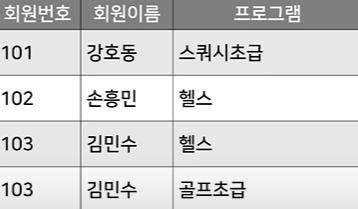
2 제 2 정규화:
모든 테이블의 Partial Dependency를 제거하는 행위.
기본적으로 각각의 행을 구분할 수 있는 컬럼을 primary key라고 부름.
한 행이 따로 그런 애가 없다면, 몇 개를 조합해서 composite primary key라고 부름.
이때 Partial Dependency라는 것은, 아래 표의 프로그램 - 가격 같은 존재. 즉, 따까리의 수장이 cpk인 경우임.
예를 들어,
아래의 식에서 헬스의 가격을 다 7000원으로 올리려면?
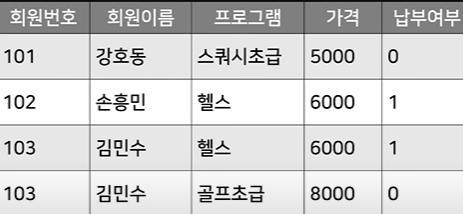
저 가격 테이블은 이 테이블의 나머지와 꼭 관련되어 있다고 보기 힘듦. 그래서 그걸 분리해주면?
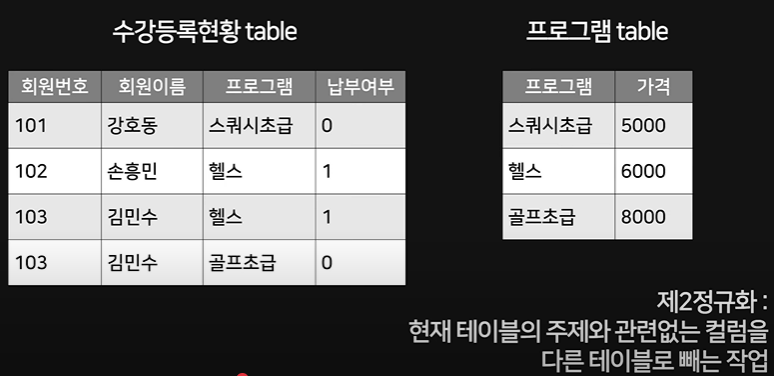
이렇게 하면 가격 바꾸기 쉽지. 그러나 단점은, 몇 개의 테이블이 생긴다는 것.
3 제 3 정규화:
제 2 정규화와 매우 유사하지만, 제 2는 composite primary key의 따깔를 제거하는 방식이었다면,
제 3은 composite primary key와 관계없는 녀석을 제거하는 방식임.
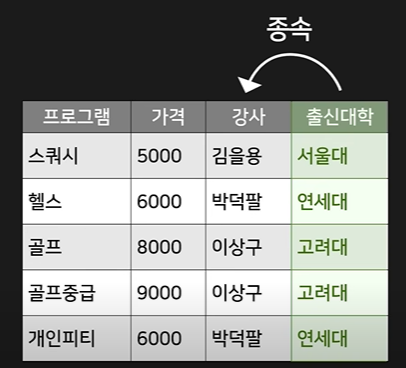
얘를 아래처럼 바꿈.
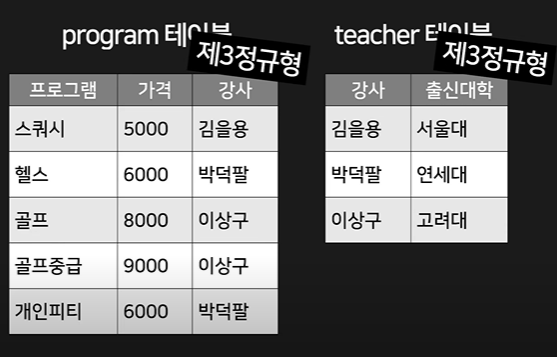
관계형 DB의 경우 1, 2, 3 정규화를 보통 진행함.
정규화의 장점: 데이터베이스 값 수정 및 구조 확장에 유리함.
정규화의 단점: 테이블이 많아서 JOIN이 늘어남.
역정규화를 하는 이유? JOIN이 너무 많아서 성능 이슈가 있는 경우 성능을 향상시키기 위함.
(6) SQL injection이란?
공격자가 악의적인 의도를 갖는 SQL 구문을 삽입하여 DB를 비정상적으로 조작하는 코드 인젝션 공격 기법.
방어하는 방법?
- 입력값을 검증하여, 입력이 쿼리에 동적인 영향을 주는 경우 이를 다시 확인함.
- 저장 프로시저, 즉 Query의 형식을 미리 지정해두는 방식으로, 특정한 커맨드만 받음.
(7) RDBMS vs NoSQL
RDBMS는모든 데이터를 2차원 테이블 형태로 표현.
데이터의 정합성이 보장되지만, 시스템 커질수록 쿼리가 복잡해지고 성능이 저하됨. scale-out 안되고 scale-up만 됨.
NoSQL은 그 반대. key - value 형태로 데이터를 관리해 자유롭게 데이터를 관리할 수 있음.
가장 큰 단점은, 데이터 중복이 발생할 수 있다는 점.
Scale up이란? 단일 서버의 성능 향상. 한마디로, 더 좋은 장비 쓰는 것.
Scale out이란? 같은 서버 여러개 붙이는 것.
(8) 트랜잭션이란?
DB에서 논리적으로 한꺼번에 수행되어야 하는 작업 단위.
예를 들면, 계좌이체: 은행계좌에서 한 계좌에서 돈을 빼고 다른 계좌에 돈을 넣는 두 작업은 하나의 트랜잭션이어야 함.
작업의 완전성을 보장해줌 - 작업들을 모두 처리하거나 처리하지 못할 경우 이전 상태로 복구하여, 작업의 일부만 적용되는 현상이 발생하지 않게 만들어주는 기능. git처럼, commit, rollback 됨.
트랜잭션의 특성 ACID:
Atomicity: 트랜잭션은 모두 실행되거나, 모두 실행 안 되어야 함.
Consistency: 트랜잭션 실행 전후에 DB는 항상 일관된 상태를 유지해야 함.
Isolation: 동시에 실행되는 트랜잭션들이 서로에게 영향을 주지 않도록 독립적으로 실햄.
Durability: 진행한 트랜잭션은 영구적으로 저장해야 함. 서버 다운 등이 생겨도 데이터 손실 없도록.
(9) DB lock?
DB lock은 트랜잭션 처리의 순차성을 보장하기 위한 방법 (크게는 Isolation을 보장하기 위한 방법)
공유락 Shared Lock - Read Lock: 읽기 시에 쓰는 락, 서로 다른 트랜잭션끼리 동시에 읽기는 가능.
배타락 Exclusive Lock - Write Lock: 데이터를 변경할 때 쓰는 락으로, 트랙잭션이 완료될 때까지 다른 어떤 접근도 불허.
(10) 옵티마이저는? 주어진 쿼리를 가장 효율적으로 실행할 수 있는 방법을 구하는 SQL 내부의 두뇌.
(11) DB 튜닝이란?
DB 구조나, DB 자체, OS 등을 조정하여 DB 시스템의 전체적인 성능을 개선하는 작업을 말함.
DB 설계 튜닝 -> DBMS 튜닝 -> SQL 튜닝 단계로 진행 가능.
과하게 진행하면, 데이터 변경 작업 시 느려지고, 또 관리 어려워 줌.
(12) DB 클러스터링과 리플리케이션의 차이?
클러스터링이란, 여러 개의 DB를 수평적인 구조로 구축하는 방식. 동기 방식으로 사용.
여러 개의 DB가 쓰이므로, 하나의 DB에 몰리는 부하를 분산할 수 있음. 또 시스템 장애를 방지할 수 있음.
다만 병목 현상이 일어날 수 있음.
리플리케이션이란, 여러 개의 DB를 수직적인 구조로 구축하는 방식. 비동기 방식으로 사용.
비동기 방식으로 운영되어 지연시간이 거의 없고, 읽기 작업에 있어 성능이 높아지지만, 동기화가 보장 안되어 일관성 있는 데이터를 보장할 수 없음.
단순히 여러개의 서버를 가져서 빨라지는 게 아니라, primary 역할하는 DB는 쓰기만 하고, replica 역할하는 읽기만 함.
'백엔드 잡학사전' 카테고리의 다른 글
| [스프링 리뷰] (1) | 2024.09.14 |
|---|---|
| [스프링 핵심] 빈 스코프 & 프로토타입 빈 (0) | 2024.08.20 |
| [스프링 핵심] 빈 생명주기 콜백 (0) | 2024.08.20 |
| [스프링 핵심] 의존관계 자동 주입 +α (0) | 2024.08.19 |
| [스프링 핵심] 컴포넌트 스캔 & 의존관계 자동 주입 (0) | 2024.08.18 |



