Spark 에서 일반적으로 데이터를 다루는 방식은 두가지로 나뉜다.
1 Spark Table - SQL
우리가 일반적으로 알고 있는 RDBMS의 개념이 spark에서의 table이라고 생각하면 됨. 스키마는 meta store에 저장.
이미 정리된 스키마를 틀로 하고, 테이블 형태로 어떤 저장소에 저장이 되는, 그런 table. 당연히 structured만 받음.
2 Spark Data Frame - DF APIs
반면 후자, 그러니까 Data Frame은 동작 방식 자체가 다르다. Run time에 생성되고, 프로그램 종료와 함께 끝남.
당연히 스키마를 관리하는 catalog (meta store가 아님)도 run time에 정립이 되었다가 끝나면 날아감.
스키마도 run time 시에, 대상이 되는 데이터 셋을 기준으로 새로이 생성되기 때문에 정해진 schema에 데이터를 욱여 넣거나 그에 맞지 않으면 버려야 하는 것이 아니라, 애초에 데이터에 맞게 스키마가 짜이는 방식인 것임.
structured, semi-structured, un-structured 모두 가능함.

이러한 차이가 있기 때문에, 각각을 활용하는 배경 및 이유에는 차이가 있음.

일회성이거나, 빠르게 데이터 가공 및 변환, ETL 작업을 하고 싶다면 DataFrame,
영구적이거나, 데이터 관리 혹은 SQL 친화적인 환경에서는 Spark Table을 써주면 됨.
아래의 미니 프로그램을 작성한다고 해보자.

fire_df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv")
똑같은 코드를, read의 format이 아닌, read의 csv 로도 쓸 수 있음. 그러나 확장성 이슈로, 첫번째 방식을 선호.
fire_df = spark.read.csv("파일경로", header="true", inferSchema="true")
DataFrame은 런타임 시의 형태이므로, 확장자가 없음. 그러나 이걸 어딘가에 저장하고 싶다면, 당연히 특정한 확장자를 정해서 저장해야 한다.
Spark SQL
그냥 언어를 SQL로 바꾸고 거기다가 SQL 쿼리 작성해주면 그만이다.
create table 하면 그게 기본적으로는 database tables - default에 들어가는데, 그러지 말고 새로운 databases 폴더를 만들고 거기에 집어넣어주면 됨.
그리고 이전에는 몰랐던 게 있는데, create table 이후에 맨 뒤에 using~ 써주면 그 확장자로 저장하라는 뜻임.
) using parquet
spark table은 million, billion의 데이터를 저장할 준비가 되어있는 녀석임. 한줄 한줄이 아닌, 보통 어떤 chunk 단위로 다루게 될 예정임.
그리고 참고로, spark SQL에서는 delete이 없음. truncate을 활용해줘야 함.
insert into demo_db.fire_service_calls_tbl
select * from global_temp.fire_service_calls_view
※ databricks community edition 에서는, 2시간 이상 서버를 활용 안 하면 해당 클러스터 VM과 메타데이터를 모두 지워버림. 그러나 storage는 안 지움. 그래서 이건 매뉴얼로 지워줘야 함. 이걸 지울 때는, warehouse 예하에서 지워야 함.
warehouse는 모든 spark 저장소가 저장되는 아브라함이므로, 그것 예하에서 지우더라도 지워야지, warehouse를 건드리면 안됨.
뿐만 아니라, table와 view 모두 drop 해줘야 함.
%fs rm -r /user/hive/warehouse/demo_db.db
drop table if exists demo_db.fire_service_calls_tbl;
drop view if exists demo_db;
아 그리고, spark에서는 %md를 쓰면 마크다운을 작성할 수 있음!
Dataframe methods
Dataframe을 다루는 것은, 큰틀에서 3 부분으로 나뉜다. Actions, Transformations, Functions/Methods.
Action은 spark job을 실행시키고 그 결과물을 spark driver에게 보고하게끔 하는 트리거 역할을 함.
Transformation은 새로 Dataframe을 만드는 역할. Functions/Methods는 나머지 것들을 일컬음.


Apply Transformation
기본적으로 data frame의 컬럼명은 standardized 되어야 함. blank 불포함해야 함. 만약 특정한 컬럼이 그렇지 않다면 standardized 시켜줘야 함. 그건 withColumnRenamed 함수로.
renamed_fire_df = raw_fire_df.withColumnRenamed("Call Number", "CallNumber")
저거 말고도 수많은 컬럼을 고쳐야 한다면? 그냥 계속 .withColumnRenamed 시전해주면 됨. 물론 비효율적이고 이를 해결할 방법은 따로 존재하지만 일단은 스킵.
※ 중요한 것은, withColumnRenamed는 부수효과가 없는 함수이기 때문에, 새로운 객체를 저장 안하면 없어짐.
기본적으로 Spark DataFrame은 불변성을 따름.
※ 그리고, datetime이어야 하는데 string 형태를 가진 컬럼은 모두 그 유형을 datetime으로 바꾸어줘야 함. 이때 쓰는 게 withColumn(,) 이 녀석임. 자주 쓰인다고 함.
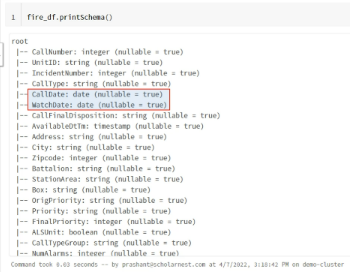
fire_df = renamed_fire_df.withColumn("Calldate", to_date("CallDate", "MM/dd/yyyy"))
이렇게 하고 나서 fire_df.printSchema() 해주면 결과가 아래와 같이 나옴.
Dataframe의 데이터를 다루는 데 있어서는 두가지 방법이 있음.
1 TempView라는 형태로 변경한 후, RDBMS처럼 SQL로 다뤄주기. 이때 쓰는 함수는 createOrReplaceTempView.
fire_df.craeteOrReplaceTempView("fire_service_calls_view")
ql_sql_df = spark.sql(""",,,""")
display(ql_sql_df)
2 변환없이, Dataframe method를 활용해서 바로 수정하는 방법도 있음. 위가 sql, 아래가 dataframe method.
select count(distinct CallType) as discint_call_type_count
from fire_service_calls_tbl
where CallType is not null
ql.df = fire_df.where("CallType is not null").select("CallType").distinct()
print(ql_df.count())
dataframe method 중 action은 dataframe을 리턴하는 게 아니라, 실행 후 spark driver에게 그 결과물을 전달함.
일반적으로 transform끼리 chain으로 마구 쓴 이후에, action을 다른 줄에 써서 실행시키는 방식임. 그게 아니라도 어쨌든 action이 필요하다면 일단 마지막은 action으로 끝나야 하고, 그것이 유일 action이어야 함.
위에서는 count가 action method.
'데이터 엔지니어링' 카테고리의 다른 글
| [Spark] 본격적인 프로그래밍 on spark 🧑💻 (0) | 2025.02.19 |
|---|---|
| [Spark] 스파크 실행 모델과 구조 (0) | 2025.02.18 |
| [Spark] Spark @ Databricks Cloud 기본 (0) | 2025.02.11 |
| [Spark] 빅데이터와 데이터 레이크 - Hadoop 변천사 (0) | 2025.02.05 |
| [Airflow] Airflow 내맘대로 꾸미기 (Elasticsearch, plugin) (0) | 2025.02.04 |



