
Spark가 특정한 데이터를 받아서 처리하게끔 하는 부분이 1번 부분이고, 이게 사실 가장 중요하고, 앞으로도 이 부분을 위주로 다룰 것이다. 그 전에, 다 만든 Spark 프로그램이 batch든 streaming이든 그 사이에 포함이 된다고 하면 어떻게 실행하는지를 알아보면,

일반적으로 단위 테스트 등 코드를 작성할 때는 interactive clients를 활용하지만, 다 끝나고 나면 submit을 해야 하는데 그 방법이 여러개 있다. 우선 가장 보편적으로 쓰이는 게 spark-submit이지만, databricks notebook을 이용해서 개발했다면 databricks가 제공하는 submit이 있기도 하고, 그리고 서로 다른 플랫폼에서 제공하는 RestAPI도 있음. 막론하고 보편적으로 쓰이는 것은 spark-submit.
Spark 분산 처리 모델

간단하다.
클라이언트가 완성된 애플리케이션(혹은 spark 프로그램)을 제출 =>
Spark 엔진이 cluster manager에게 container와 리소스 제공하라고 명령 =>
cluster manager가 컴퓨터 하나 잡고 니가 처리하라고 지정, 걔가 driver가 됨 =>
driver가 각을 보고, 필요한만큼의 노드들을 잡아서 진짜 executor로 지정, 얘네가 일 다 함.
각각의 애플리케이션에 대해 따로따로 이렇게 진행됨. 서로 다른 컨테이너에서 진행되기 때문에 병렬적으로 실행가능.
* 1: 그러면 cluster를 제공 안하는 Local Machine에서의 Spark는 어떻게 작동하는지?

configuration 과정에서 local[n] 이렇게 선언해두면 알아서 local 리소스를 돌림. 예를 들어, pycharm 같은 것을 쓰면, databricks 클러스터를 활용 못하는데, 그때 config에 들어가보면 local[n]이라고 뜸. n은 배정한 cpu 코어의 개수인데, 만약 1로 지정하면 driver가 executor의 역할까지 모두 해야하므로 비효율적. 3으로 하면? 1 driver, 2 executor. *으로 하면 최대 성능을 위해 모든 코어 사용.
* 2: 제출 안하고 run만 시키는 interactive clients는 어떻게 Spark를 실행시키는지?
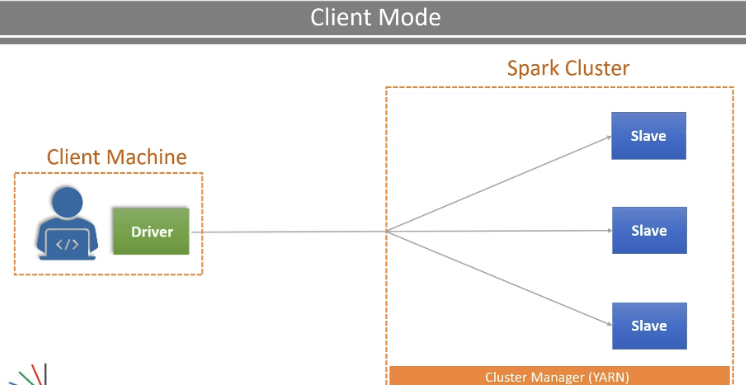
핵심은, 클라이언트의 쪽에 driver가 붙어있다는 점이다. 그래서 실행시킬 때마다 submit 안해도 spark cluster를 slave로 활용하는 것. 다만 log-off를 하면 클라이언트가 driver가 죽기 때문에 전체가 소멸된다. 그래서 long-term으로 하는 작업은 이러한 모드가 아니라, cluter mode가 적절한 것.
정리해보면 아래와 같다.

저 중에서 가장 많이 쓰이는 실행 방식에 대해 demo 해보자.
1 PySpark Shell on Local Client Mode
1 spark binaries를 local machine에 설치.
2 cmd에서 아래 코드 시전하면 spark shell 켜짐.
--master local[3] --driver-memory 2G
3 거기서 실행한 것들은 local browser에서 UI로 확인 가능.

2 Multi-Node Spark Cluster in GCP
1 GCP에 입장해서, Dataproc 섹션 > Clusters: spark를 바로 활용할 수 있는 on-demand YARN 클러스터임!
2 클러스터 필요한만큼 만들고, 그 앞단에 zeppelin이든 jupyter든 붙여서 쓰면 됨. 익숙한 저 UI를 즐기면 됨.
3 저 앞단에 뭘 쓰는지에 따라 이후가 다른데,
(1) spark-shell을 쓰고 싶다면, 기존의 local resources를 쓸때는 cmd에서 해준 것처럼, 이번에는 GCP 에서 ssh를 통해 화면을 켜주고 거기에 같은 코드를 쳐서 시작하면 됨.
착한 GCP는 web interfaces라는 단에서 YARN ResourceManager 혹은 Spark History Server 등의 기능을 함께 제공하므로, 그 UI를 볼수도 있음.
(2) zeppelin이든 뭐든 쓰고 싶다면, web interfaces에서 그걸 골라서 눌러주면 됨. 그 interaction mode에 들어가서, 먼저 cluster와 연결시켜주고, 그러고 사용하면 됨.
'데이터 엔지니어링' 카테고리의 다른 글
| [Spark] Spark의 매우 도움되는 API 친구들 (0) | 2025.02.20 |
|---|---|
| [Spark] 본격적인 프로그래밍 on spark 🧑💻 (0) | 2025.02.19 |
| [Spark] Spark에서의 쌍두마차, Table 과 Data Frames (0) | 2025.02.18 |
| [Spark] Spark @ Databricks Cloud 기본 (0) | 2025.02.11 |
| [Spark] 빅데이터와 데이터 레이크 - Hadoop 변천사 (0) | 2025.02.05 |



